—ing margins of error
A bit of background, for non-computer people. Sensible programmers keep their programs in version-control systems. Among other things, these store explanatory messages for each change to the code. In a perfect world, these messages would be concise and informative descriptions of the change. Our world is sadly imperfect.
Ramiro Gomez has worked through the archives of change messages on the largest public version-control site, github, to look for “expressions of emotional content”, such as surprise and swearing, and divided these up by the programming language being used. Programmers will not be surprised to learn that Perl has the highest rate of surprise and that the C-like languages have high rates of profanity. If you want to find which words he looked for, you’ll have to read his post.
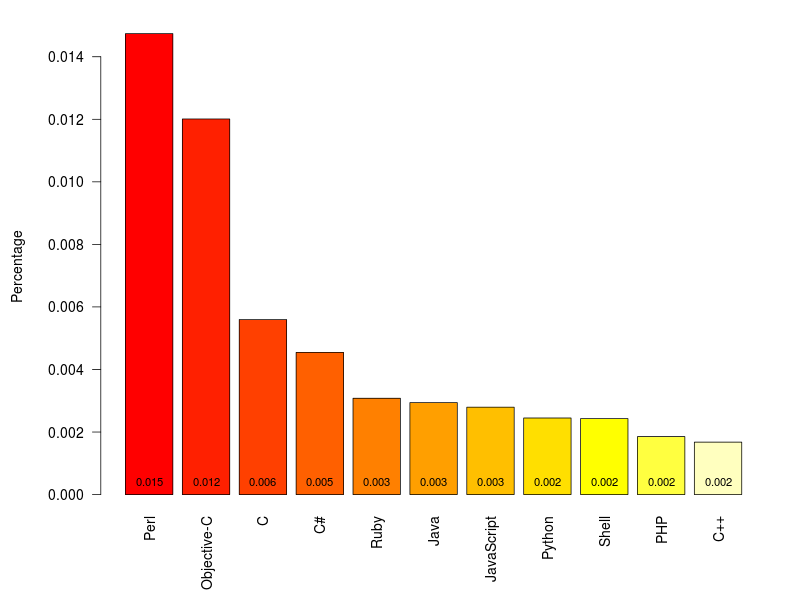
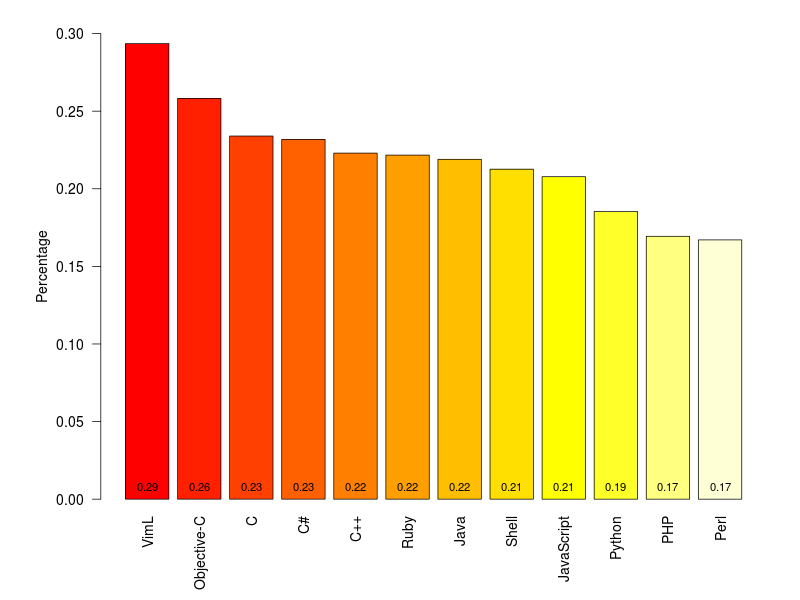
He notes
Even though a minimum of 40,000 samples per languages seemed adequate to me (I wanted to include Perl), different sample sizes result in varying accuracy, which is a problem and a bit like comparing apples and oranges. Statisticians will probably deny any value of such an approach, still I think it can serve to develop some hypotheses.
Statisticians have no problem with varying sample sizes, but we would like uncertainty estimates. That’s especially true for the ‘surprise’ category, where the number of messages is very small.
So, as a service to programmers of an inquiring disposition, here are the proportions with confidence intervals. They are slightly approximate, since I had to read the sample sizes off the graph.
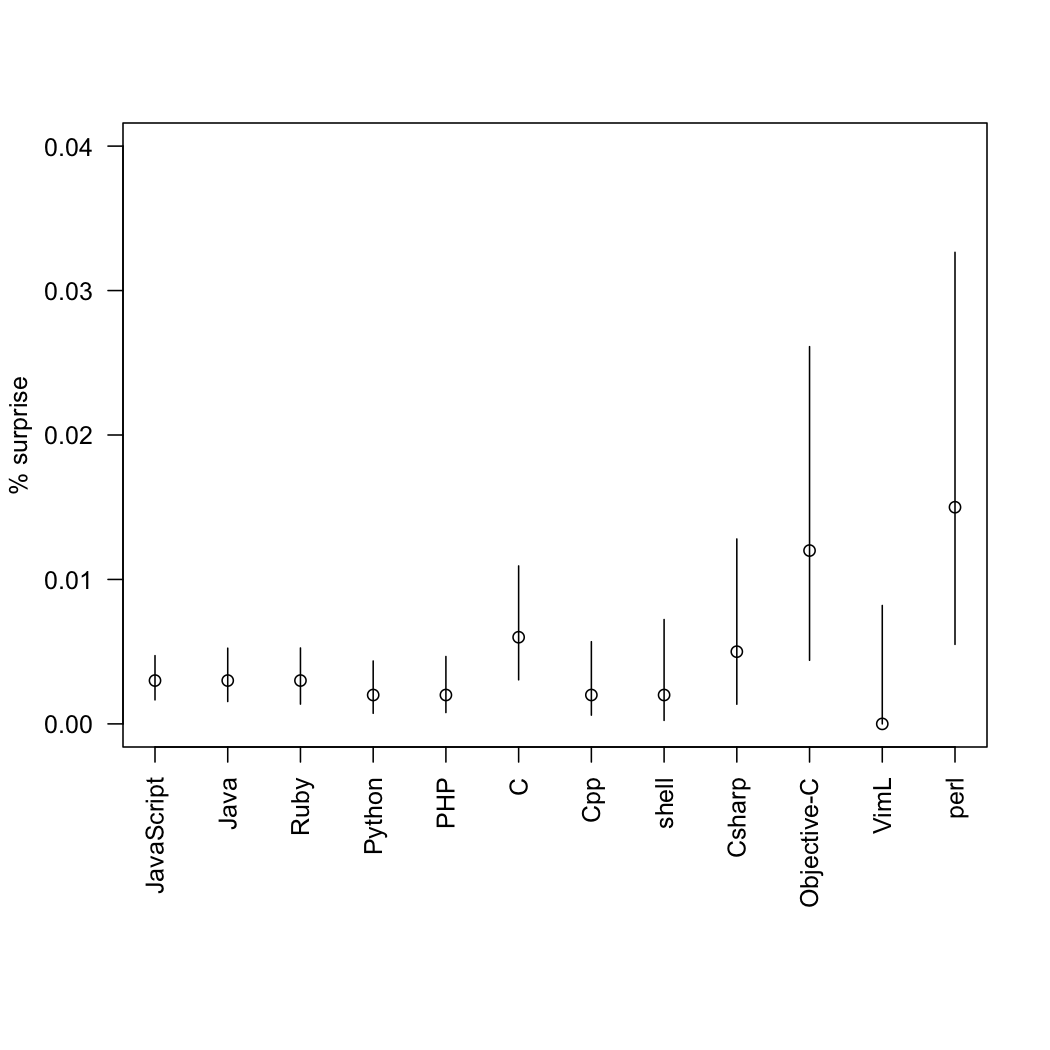
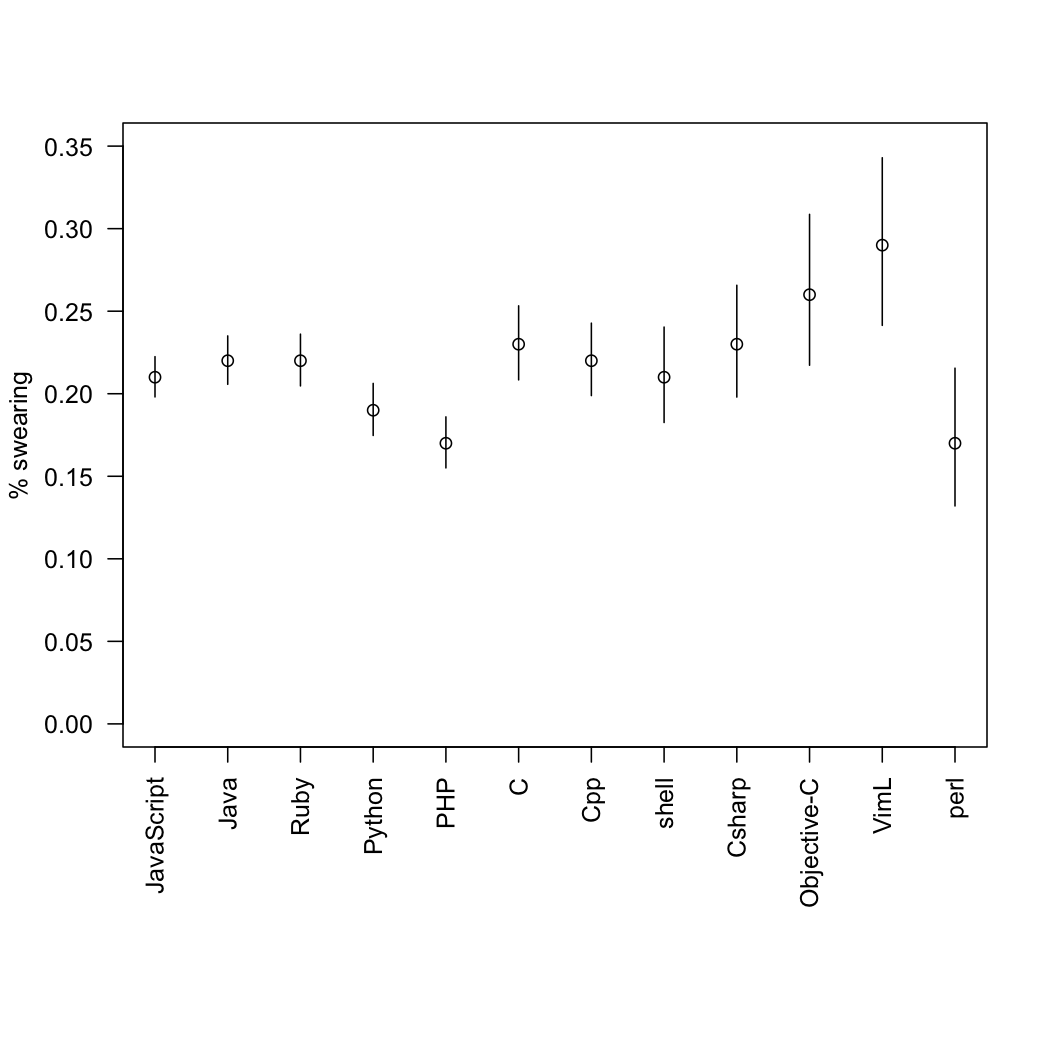
(via @TheAtavism and @teh_aimee)
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »
Nice work. I loved the regular expressions he used. My only disappointment and surprise is that I didn’t find “braindead” mentioned. Nor “kludge”. Perhaps they aren’t considered emotive enough.
11 years ago
I imagine there are some confounding variables here too – perhaps the age of the programmer – the newer, sexier languages are probably positively skewed in this regard I would guess.
11 years ago
That’s probably why PHP results in less surprise and swearing that you’d expect: it may be mostly used by a more sedate generation.
11 years ago
Thanks for sharing and commenting on the article.
Made me realize that I really should include the CSV files used to create the graphs, as it is too much of a hastle to recreate with the scripts.
So I did that and they are now in the GitHub repo https://github.com/yaph/gh-emotional-commits
11 years ago