London card clash sensitivity analysis
The data blog of the Daily Mirror reports a problem with ‘card clash’ on the London Underground. You can now pay directly with a debit card instead of buying a ticket — so if you have both a transport card and a debit card in your wallet, you have the opportunity to enter with one and leave with the other and get overcharged. Alternatively, you can take the card out of your wallet and drop it. Auckland Transport has a milder version of the same problem: no-touch credit cards can confuse the AT HOP reader and make it not recognise your card, but you won’t get overcharged unless you don’t notice the red light.
They looked at numbers of cards handed in at lost-and-found across the London Underground over the past two years (based on FOI request)
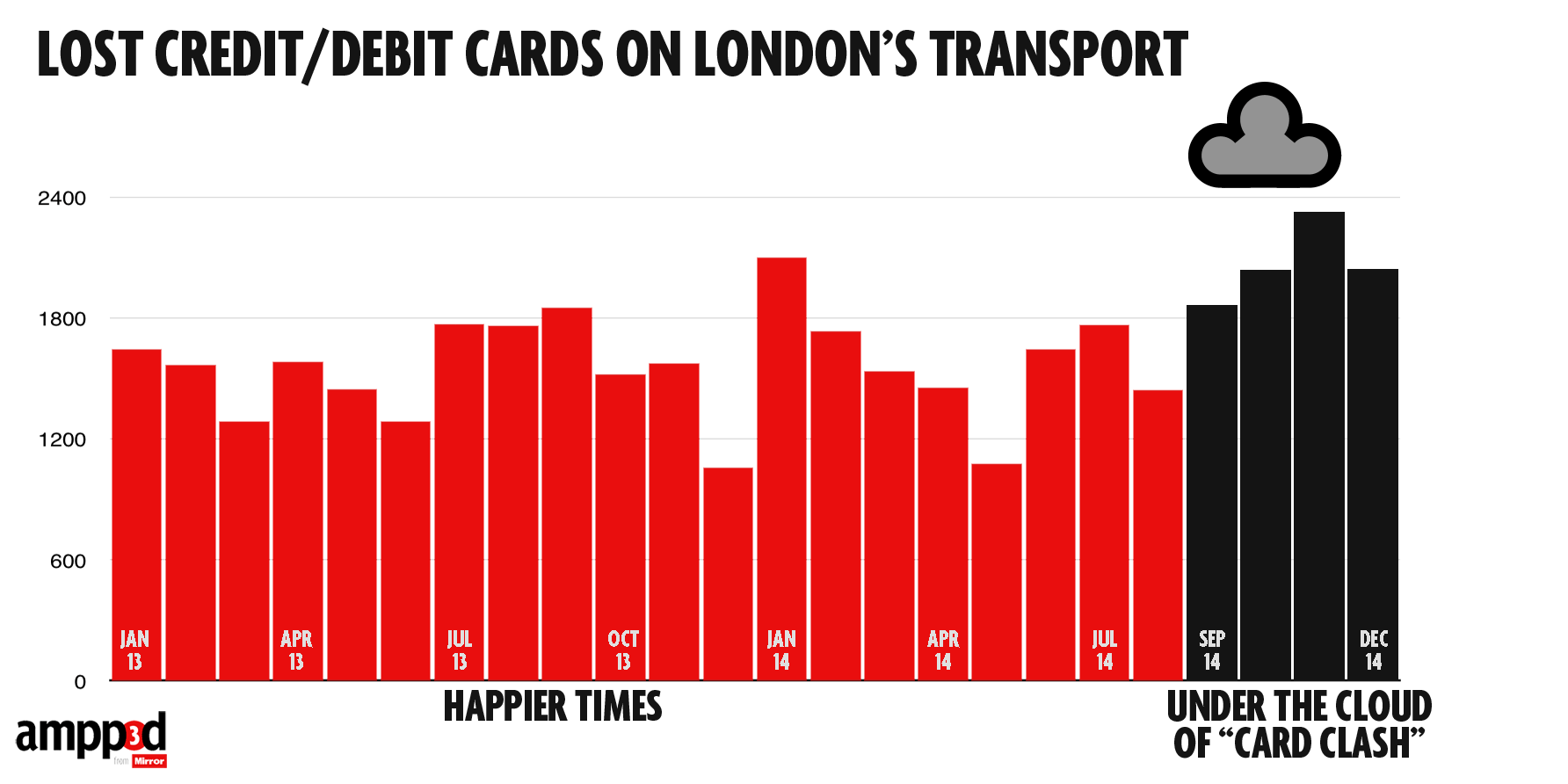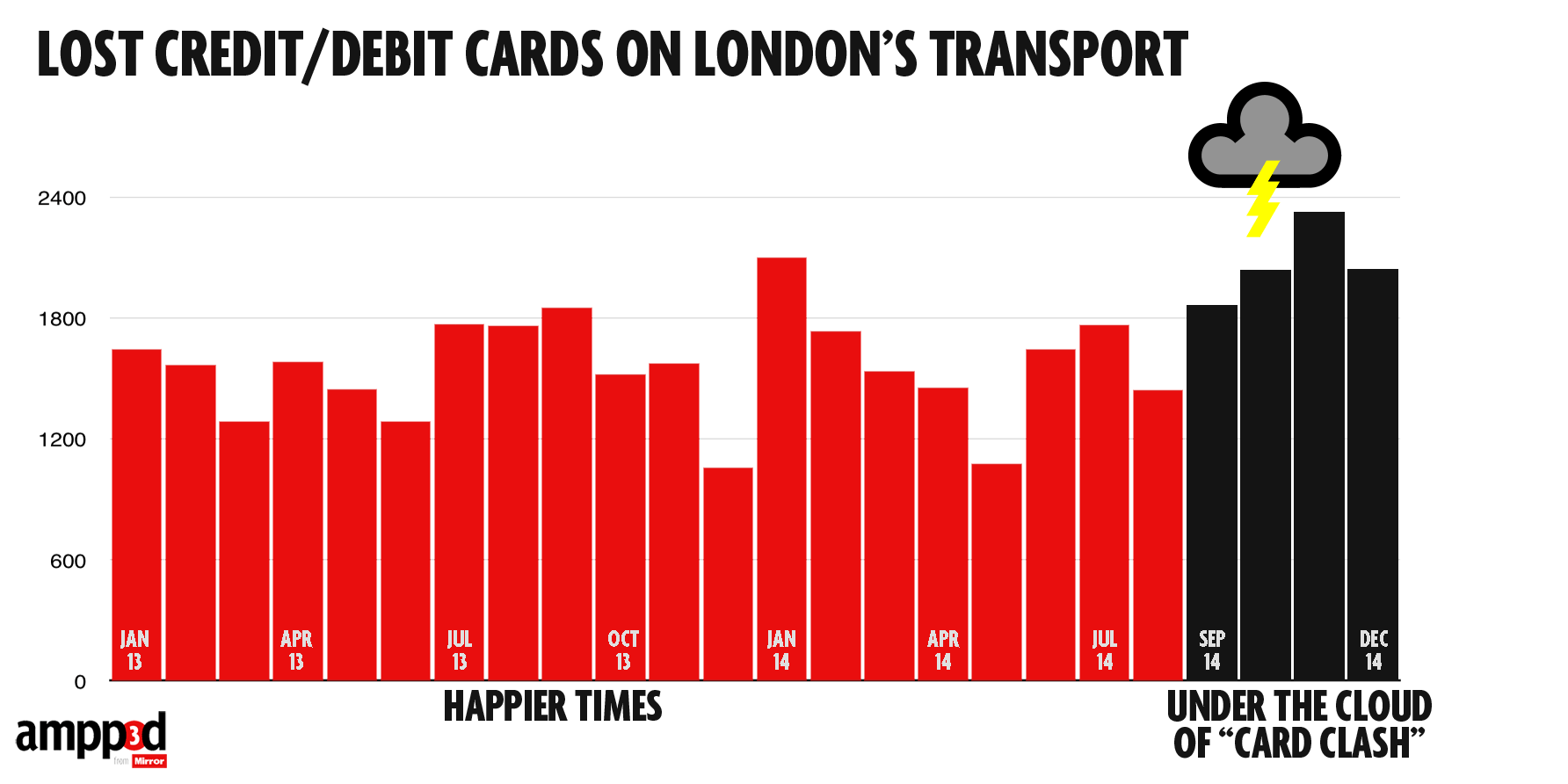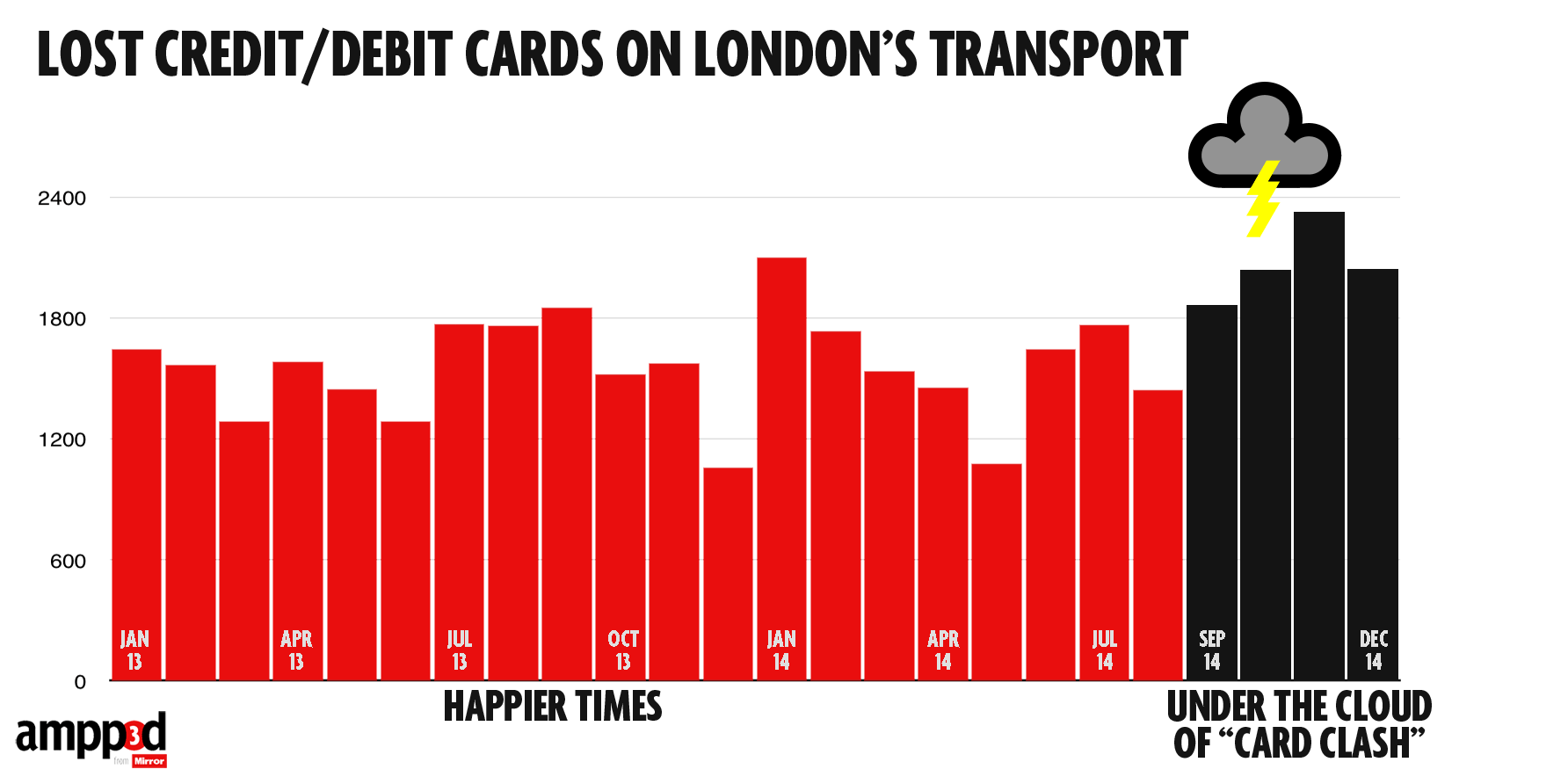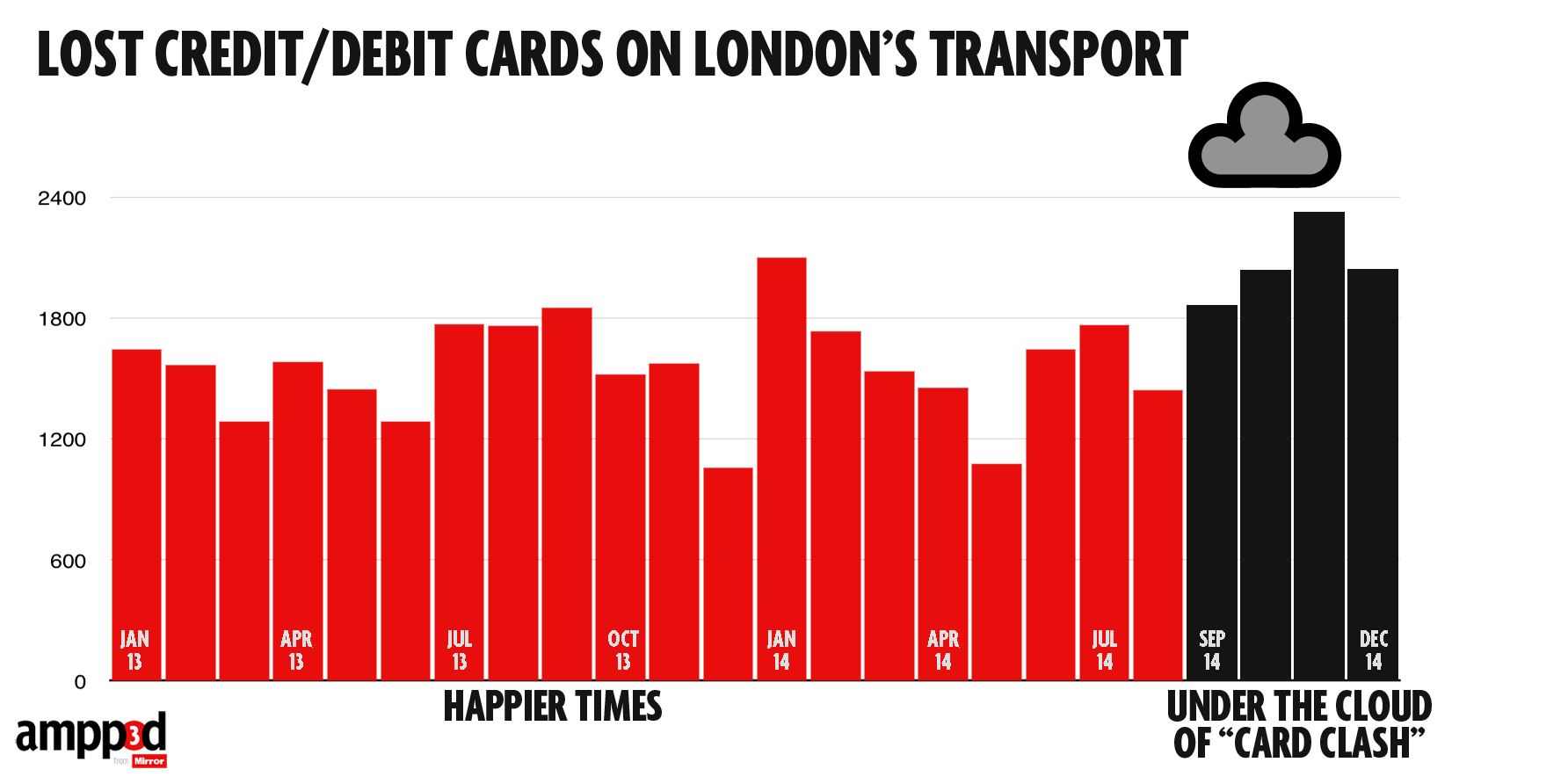
If we’re going to spend time on this, we might also consider what the right comparison is. The data include cards on their own and cards with other stuff, such as a wallet. We shouldn’t combine them: the ‘card clash’ hypothesis would suggest a bigger increase in cards on their own.
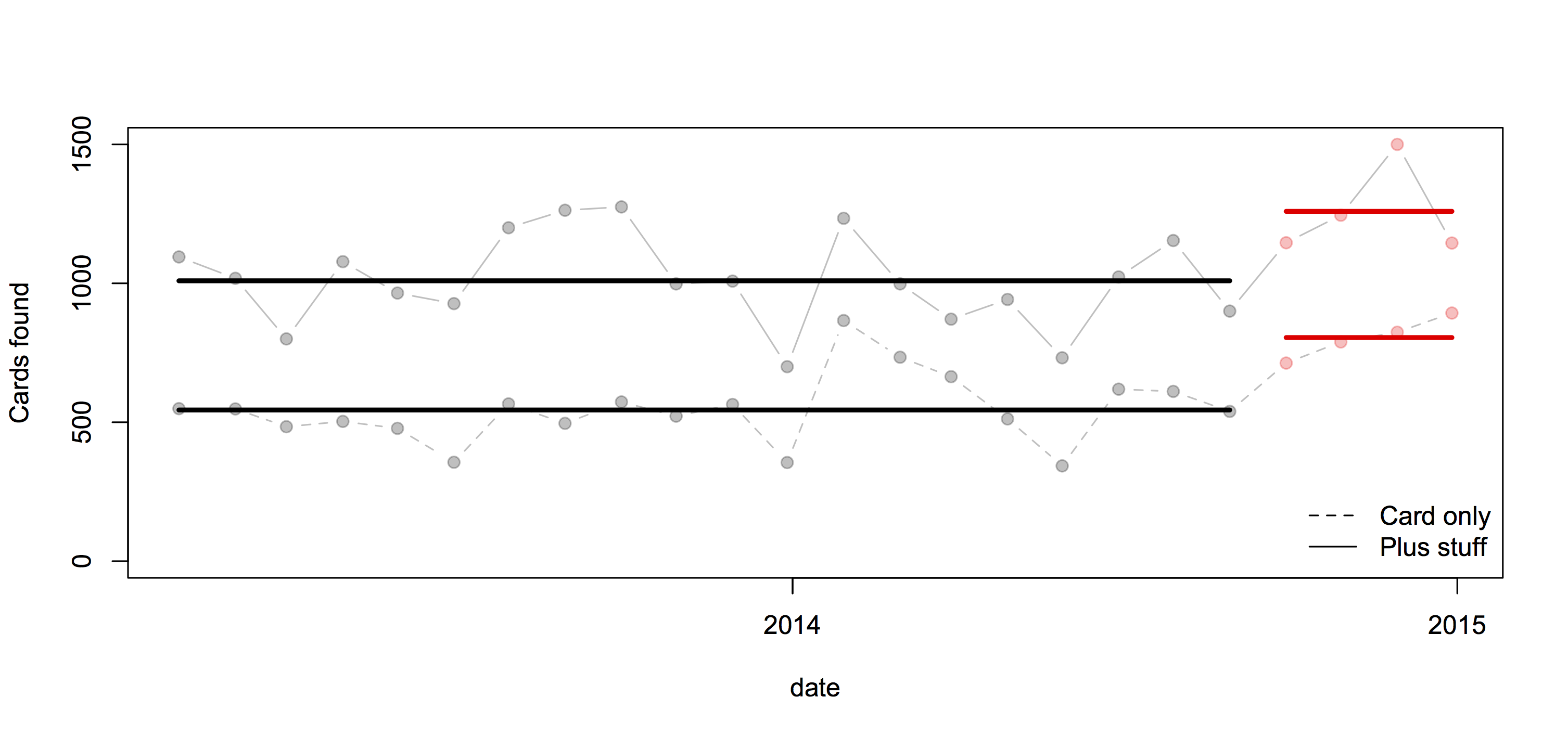
Here’s a comparison using all the data: the pale points are the observations, the heavy lines are means.
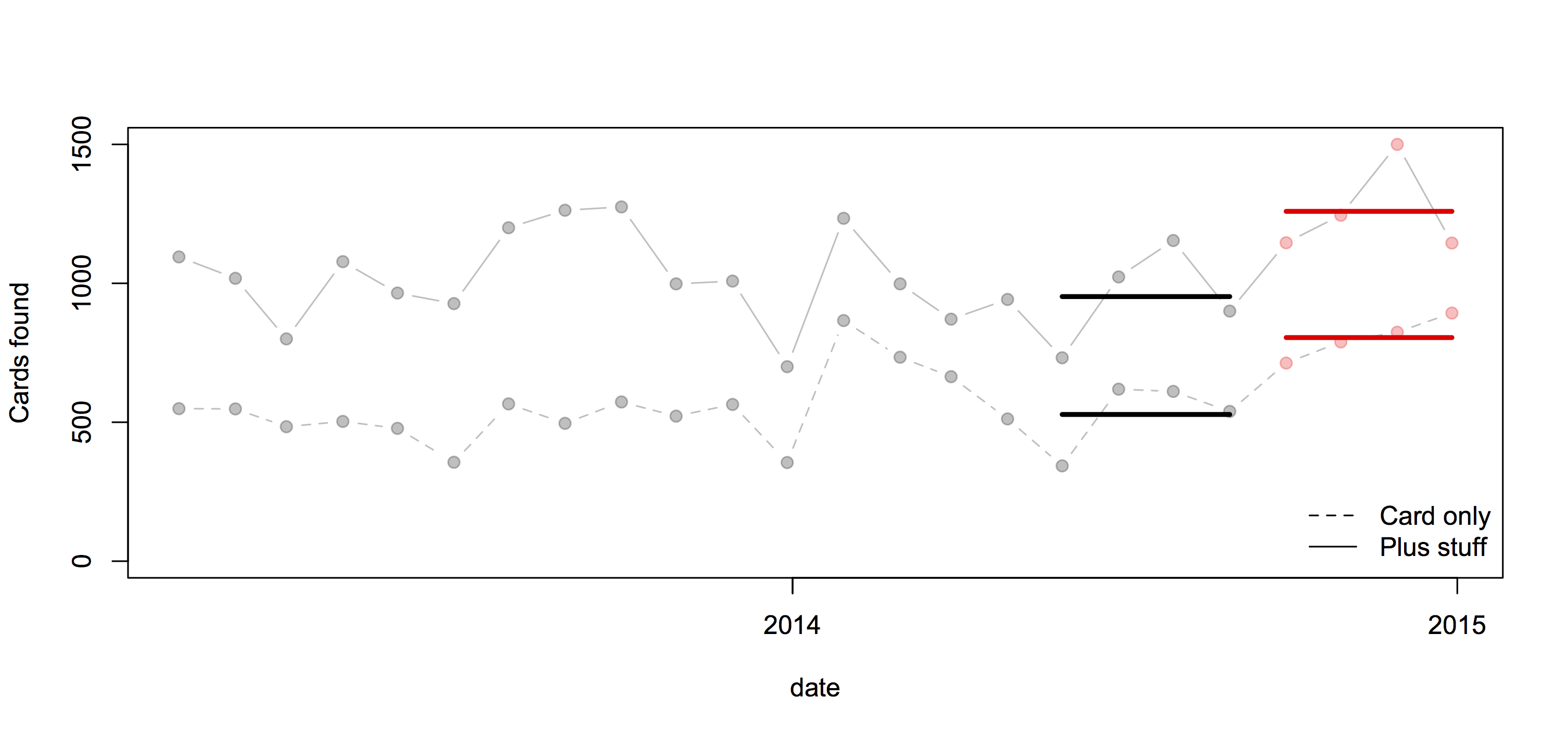
Or, we might worry about trends over time and use just the most recent four months of comparison data:
Or, use the same four months of the previous year:
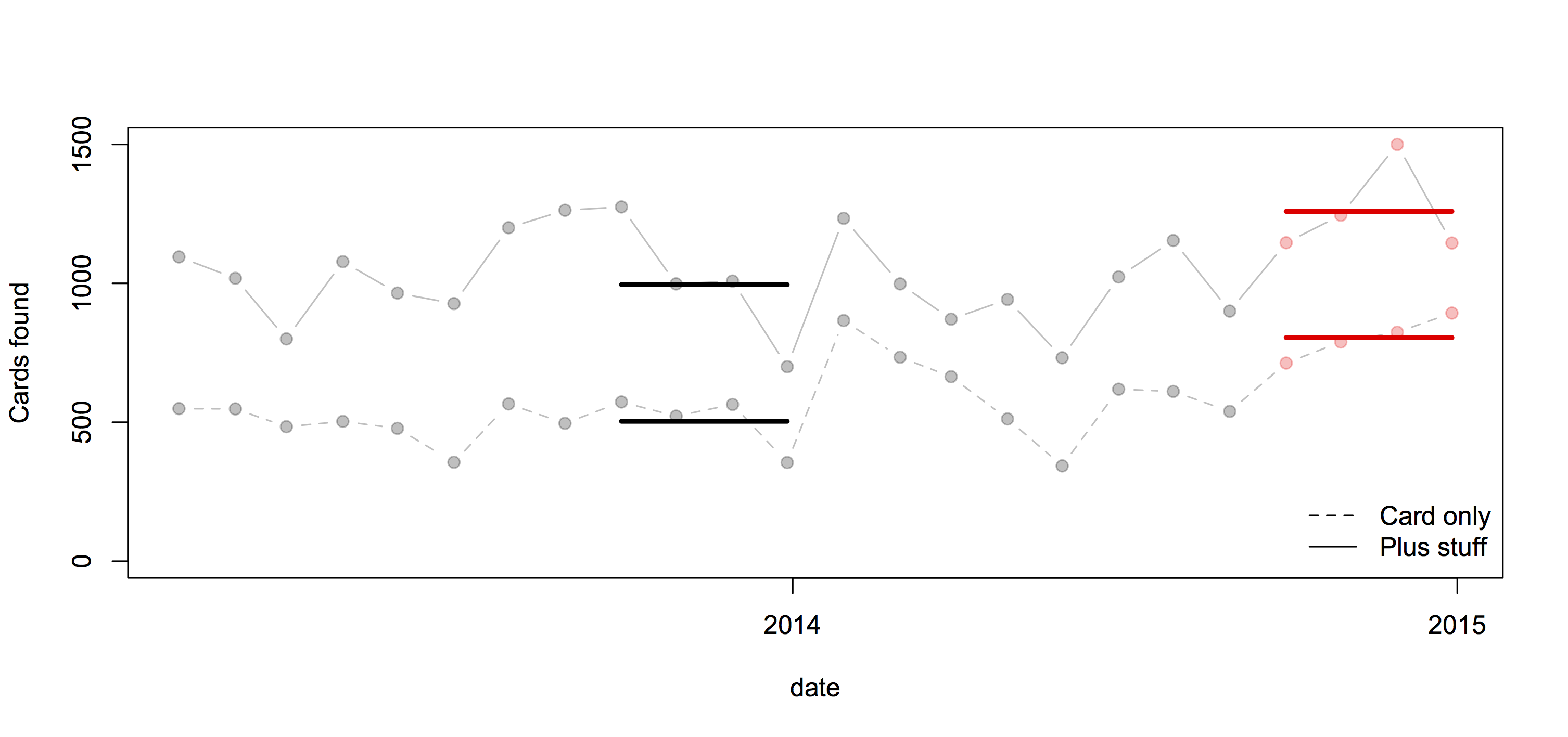
In this case all the comparisons give basically the same conclusion: more cards are being handed in, but the increase is pretty similar for cards alone and for cards with other stuff, which weakens the support for the ‘card clash’ explanation.
Also, in the usual StatsChat spirit of considering absolute risks: there are 3.5 million trips per day, and about 55 cards handed in per day: one card for about 64000 trips. With two trips per day, 320 days per year, that would average once per person per century.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »