The statistical significance filter
Attention conservation notice: long and nerdy, but does have pictures.
You may have noticed that I often say about newsy research studies that they are are barely statistically significant or they found only weak evidence, but that I don’t say that about large-scale clinical trials. This isn’t (just) personal prejudice. There are two good reasons why any given evidence threshold is more likely to be met in lower-quality research — and while I’ll be talking in terms of p-values here, getting rid of them doesn’t solve this problem (it might solve other problems). I’ll also be talking in terms of an effect being “real” or not, which is again an oversimplification but one that I don’t think affects the point I’m making. Think of a “real” effect as one big enough to write a news story about.
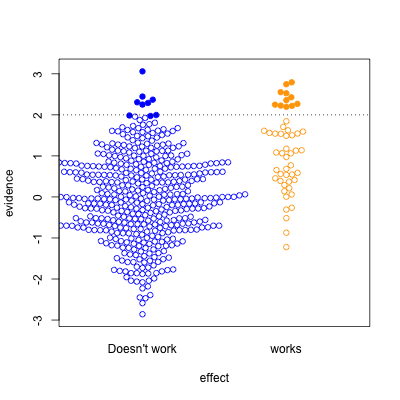
This graph shows possible results in statistical tests, for research where the effect of the thing you’re studying is real (orange) or not real (blue). The solid circles are results that pass your statistical evidence threshold, in the direction you wanted to see — they’re press-releasable as well as publishable.
Only about half the ‘statistically significant’ results are real; the rest are false positives.
I’ve assumed the proportion of “real” effects is about 10%. That makes sense in a lot of medical and psychological research — arguably, it’s too optimistic. I’ve also assumed the sample size is too small to reliably pick up plausible differences between blue and yellow — sadly, this is also realistic.
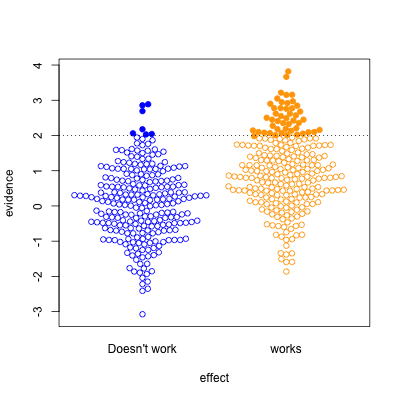
In the second graph, we’re looking at a setting where half the effects are real and half aren’t. Now, of the effects that pass the threshold, most are real. On the other hand, there’s a lot of real effects that get missed. This was the setting for a lot of clinical trials in the old days, when they were done in single hospitals or small groups.
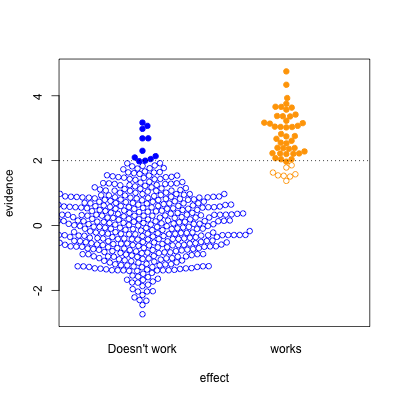
The third case is relatively implausible hypotheses — 10% true — but well-designed studies. There are still the same number of false positives, but many more true positives. A better-designed study means that positive results are more likely to be correct.
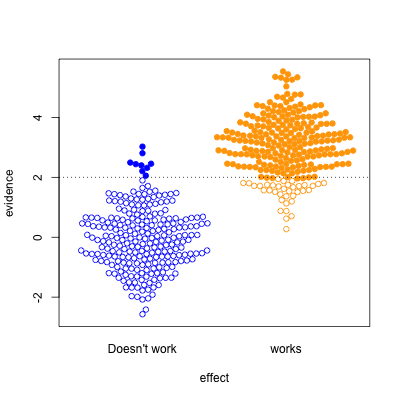
Finally, the setting of well-conducted clinical trials intended to be definitive, the sort of studies done to get new drugs approved. About half the candidate treatments work as intended, and when they do, the results are likely to be positive. For a well-designed test such as this, statistical significance is a reasonable guide to whether the effect is real.
The problem is that the media only show a subset of the (exciting) solid circles, and typically don’t show the (boring) empty circles. So, what you see is
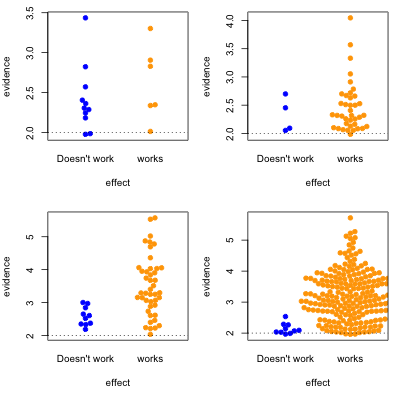
where the columns are 10% and 50% proportion of studies having a true effect, and the top and bottom rows are under-sized and well-design studies.
Knowing the threshold for evidence isn’t enough: the prior plausibility matters, and the ability of the study to demonstrate effects matters. Apparent effects seen in small or poorly-designed studies are less likely to be true.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »
Is this why the Editor in Chief of Britains Lancet said
“The case against science is straightforward: much of the scientific literature, perhaps half, may simply be untrue.”
8 years ago
Yes, though in the scientific literature the bias is less strong, and the readership presumably a bit more aware of it.
8 years ago
Thomas, what do you mean by “the prior plausibility matters”? Do you mean the hypothesis needs to make theoretical sense, or are you referring to some Bayesian thing?
8 years ago
It doesn’t *have* to be a Bayesian thing (except for people who think everything has to be). Sometimes there’s good historical data on success rates — treatments in Phase III clinical trials really do work about half the time (though some of that is toxicity rather than ineffectiveness). Sometimes there are theoretical reasons, either on the level of individual treatment (homeopathy) or collectively –maybe some minor change in presentation could have a big effect on probability of donating money, but it’s implausible that hundreds of minor changes could.
The only difference between types of prior information is in the type of conclusion. If there’s good historical data then everyone should agree; if it’s just subjective then all we can say is that everyone with similar prior beliefs should agree.
8 years ago
The majority of phase 3 trials at present are for oncology indications, but sadly the success rates in oncology are rather lower than 50% (though such figures and even higher tend to be used in investment circles), especially when only novel rather than me-too type of products with a similar mode of action are included. Although now somewhat dated, the review by Zia (Zia M. et al. Comparison of outcomes of phase 2 studies and subsequent randomised control studies using identical chemotherapeutic regimens. J Clinical Oncology 2005; 23 (28): 6982-6991) would suggest a figure of 28% to more realistic than 50% even before real therapeutic novelty is taken into account. There are several reasons to believe that the true figure is considerably lower than 28%, for example as assessed by the number of oncology phase 3 trials running and the time they take vs. the annual number achieving US registration on the basis of positive phase 3 trials.
So perhaps the situation as so nicely displayed in your graphics is not that comforting, even with well-designed trials, as a prior of 50% would be harder to support than 20%.
8 years ago
Dividing drugs into ‘novel’ and ‘me-too’ without a third category suggests that everything that isn’t first in class is being called ‘me-too’. I don’t that’s a reasonable use of the term.
For example, lots of drug companies have tried to produce CETP inhibitors. If anacetrapib turns out well next year it will be ‘novel’, but if evacetrapib had turned out well last year, anacetrapib would have retroactively become a ‘me-too’ drug after years of development.
We need a name for drugs that were developed over the same time period as the first-in-class drug, but didn’t make it out first. These will tend to have higher success rates.
We also need a name for genuinely superior drugs that use an existing mechanism — such as the huge tolerability improvements in HIV treatment since the first HAART regimens.
8 years ago