The MMP voting system and its implications are relatively complicated. I’m going to try to give simple approximations and then corrections to them. If you want more definitive details, here’s the Electoral Commission and the Electoral Act.
Two votes: You have an electorate vote, which only affects who your local MP is, and doesn’t affect the composition of Parliament. You also have a party vote that affects the composition of Parliament, but not who your local MP is. The number of seats a party gets in Parliament is proportional to the number of party votes it gets.
This isn’t true, but it’s actually a pretty good working approximation for most of us.
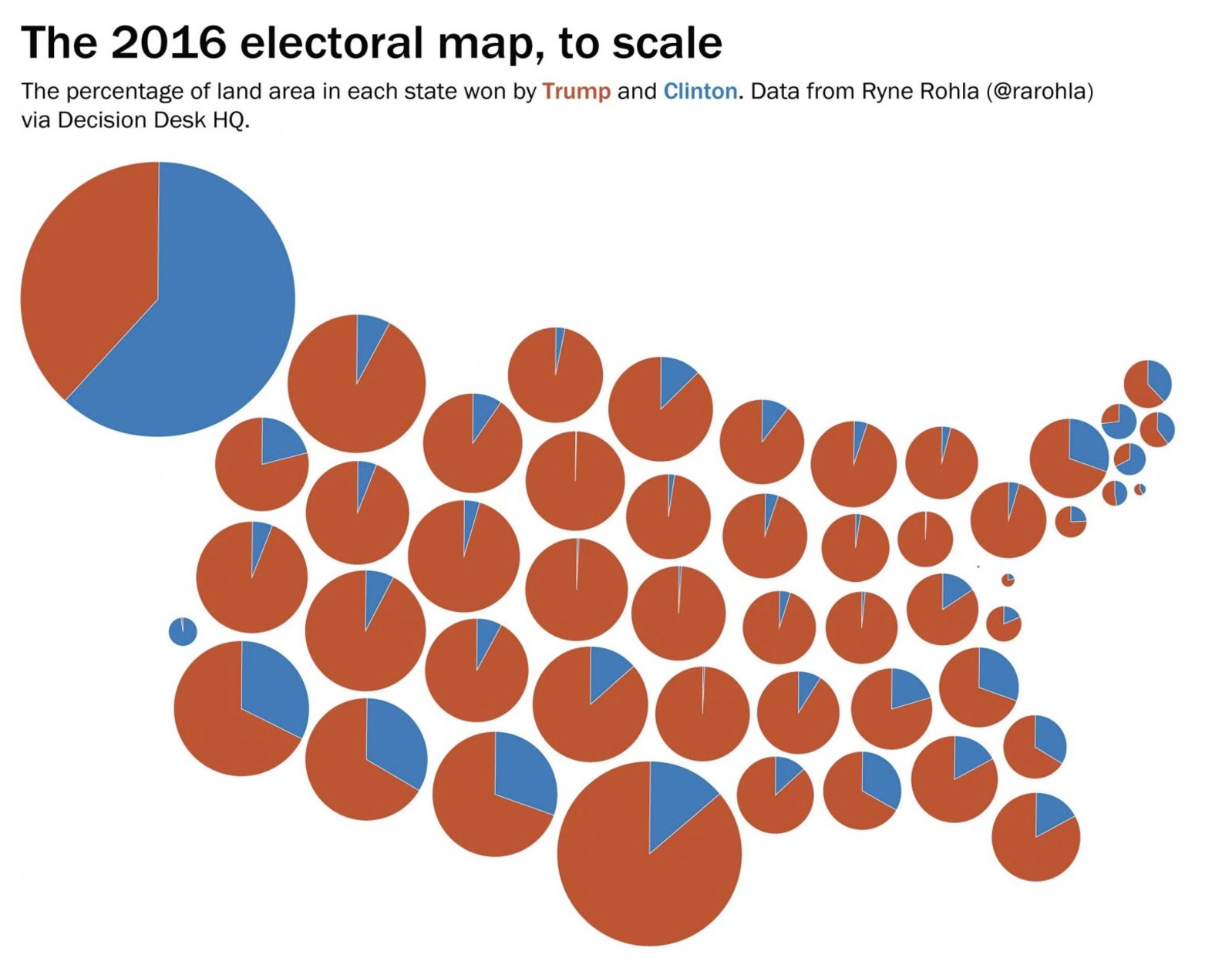
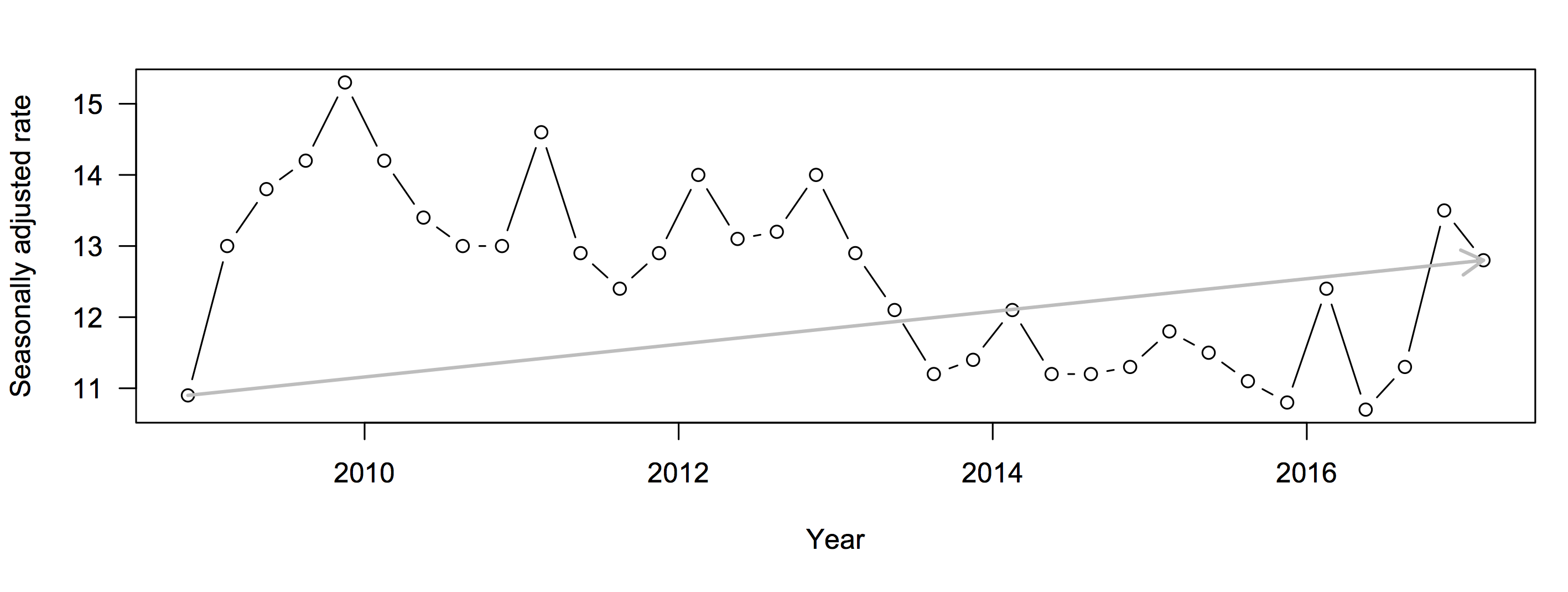
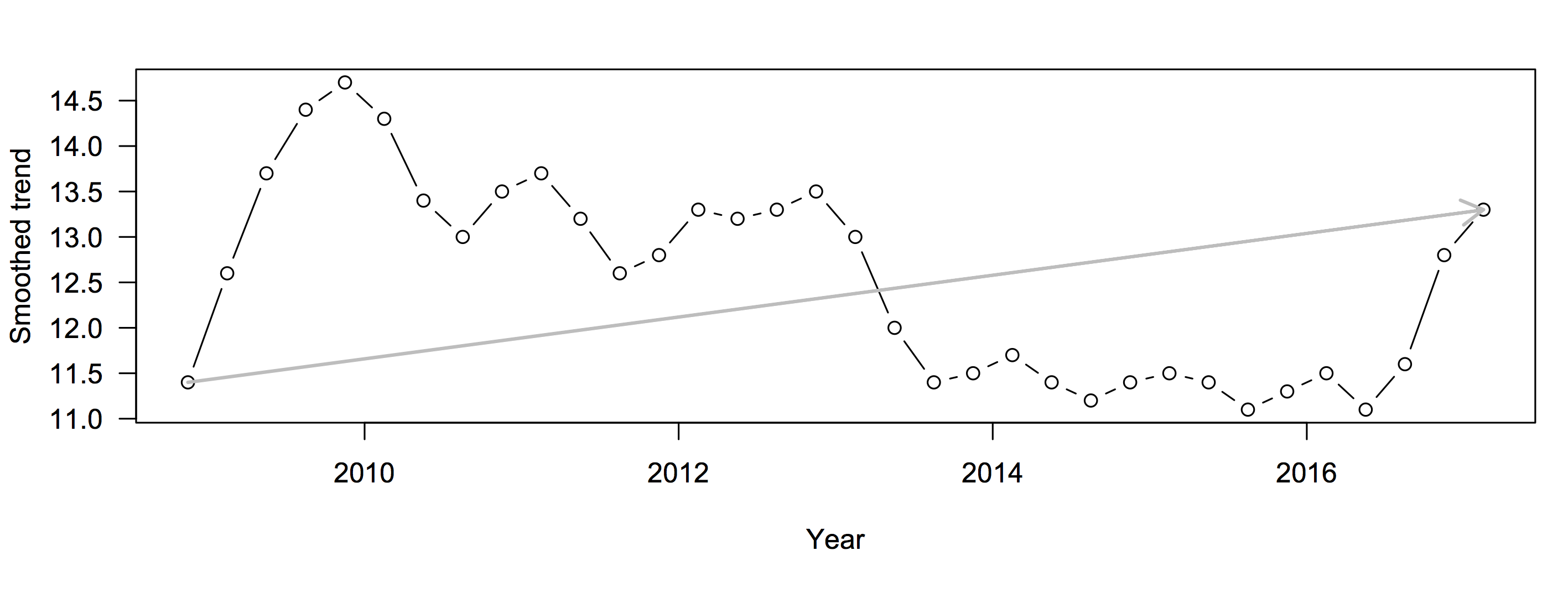
There are two obvious flaws. First, if your local MP belongs to a party that doesn’t get enough votes to have any seats in Parliament, they still get to be an MP. Peter Dunne in Ōhariu was an example of this in the 2014 election. Second, when working out the number of seats a party is entitled to in Parliament, parties with less than 5% of the vote are excluded unless they won some electorate. In the 2014 election, the Conservative Party got 3.97% of the vote, but no seats.
The Māori Party was an example of both exceptions: they did get enough votes in proportional terms for two seats, but not enough to make the 5% cutoff, but they didn’t have to because Te Ururoa Flavell won the Waiāriki electorate seat for them.
Proportionality: There are 120 seats, so a party needs 1/120th, or about 0.83%, of the vote for each one.
That’s not quite true because of the 5% threshold, both because some parties miss out and because the relevant percentages are of the votes remaining after parties have been excluded by the threshold.
It’s also not true because of rounding. We elect whole MPs, not fractional ones, so we need a rounding rule. Roughly speaking, half -seats round up. More accurately, suppose there is some number N of votes available per seat (which will be worked out later). If you have at least 0.5×N votes you get one seat, 1.5×N gets you two seats, 13.5×N gets you fourteen seats. So what’s N? It’s roughly 1/121th (0.83%) of the votes; it’s exactly whatever number you need to allocate exactly as many seats as you have available. (The Electoral Commission actually uses a procedure that’s identical in effect to this one and easier to compute, but (I think) harder to explain).
In 2014, the Māori Party got 1.32% of the vote, which is a bit more than 1.5×0.83%, and were entitled to two seats. ACT got less than 0.83% but more than 0.5×0.83% and were entitled to one seat.
Finally, if a party gets more seats from electorate candidates than it is due by proportionality those seats are extra, above the 120-seat ideal size of Parliament — except that seats won by a party or individual not contesting the party vote do come out of the 120-seat total. So, in 2014, ACT got enough party votes to be due one of the 120 seats, but United Future didn’t. United Future did contest the party vote so Peter Dunne’s seat did not come out of the 120-seat total — he was an ‘overhang’ 121st MP. I’m guessing the reason overhangs by parties contesting the party vote are extra is that you don’t know how many there will be until you’ve done the calculation, so you’d have to go back to the start and recalculate if you counted them in the 120 (which might change the number of over-allocated seats and force another recalculation and so on).
Māori Roll: People of Māori descent can choose, every five years, to be on a Māori electoral roll rather than the general roll. If enough of them do, Māori electorates are created with the same number of people as the general electorates. There are currently seven Māori electorates, representing just over half of the people of Māori descent. As with any electorate, you don’t have to be enrolled there to stand there; anyone eligible to be an MP can stand.
The main way this is oversimplified is because of the people of Māori descent who aren’t on either roll, because they’re too young or just not enrolled yet. You can’t tell whether they would be on the general roll or the Māori roll, so there are procedures for StatsNZ to split the non-enrolled Māori-descent population up to calculate electorate populations.