Kinds of fairness worth working for
Machine learning/statistical learning has a very strong tendency to encode existing biases, because it works by finding patterns in existing data. The ability to find patterns is very strong, and simply leaving out a variable you don’t want used isn’t enough if there are ways to extract the same information from other data. Because computers look objective and impartial, it can be easier to just accept their decisions — or regulations or trade-secret agreements may make it impossible to find out what they were doing.
That’s not necessarily a fatal flaw. People learn from existing cases, too. People can substitute a range of subtler social signals for crude, explicit bigotry. It’s hard to force people to be honest about how they made a decision — they may not even know. Computer programs have the advantage of being much easier to audit for bias given the right regulatory framework; people have the advantage of occasionally losing some of their biases spontaneously.
Audit of black-box algorithms can be done in two complementary ways. You can give them made-up examples to see if differences that shouldn’t matter do affect the result, and you can see if their predictions on real examples were right. The second is harder: if you give a loan to John from Epsom but not to Hone from Ōtara, you can see if John paid on time, but not if Hone would have. Still, it can be done either using historical data or by just approving some loans that the algorithm doesn’t like. You then need to decide whether the results were fair. That’s where things get surprisingly difficult.
Here’s a picture from a Google interactive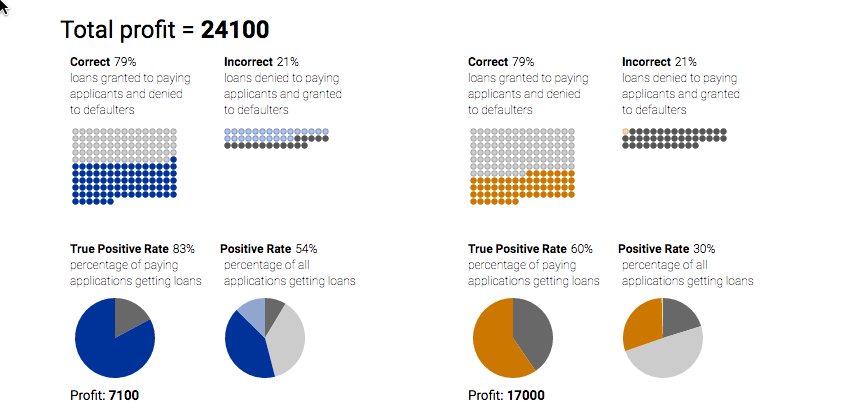
People are divided into orange and blue, with different distributions of credit scores. In this case the blue and orange people are equally likely on average to pay off a loan, but the credit score is more informative in orange people. I’ve set the threshold so that the error rate of the prediction is the same in blue people as in orange people, which is obviously what you want. I could also have set the threshold so the proportion of approvals among people who would pay back the loan was the same in blue and orange people. That’s obviously what you want. Or so the proportion of rejections among people who wouldn’t pay back the loan is the same. That, too, is obviously what you want.
You can’t have it all.
This isn’t one of the problems specific to social bias or computer algorithms or inaccurate credit scoring or evil and exploitative banks. It’s a problem with any method of making decisions. In fact, it’s a problem with any approach to comparing differences. You have to decide what summary of the difference you care about, because you can’t make them all the same. This is old news in medical diagnostics, but appears not to have been considered in some other areas.
The motivation for my post was a post at Pro Publica on biases in automated sentencing decisions. An earlier story had compared the specificity of the decisions according to race: black people who didn’t end up reoffending were more likely to have been judged high risk than white people who didn’t end up reoffending. The company who makes the algorithm said, no, everything is fine because people who were judged high risk were equally likely to reoffend regardless of race. Both Pro Publica and the vendors are right on the maths; obviously they can’t both be right on the policy implications. We need to decide what we mean by a fair sentencing system. Personally, I’m not sure risk of reoffending should actually be a criterion, but if we stipulate that it is, there’s a decision to make.
In the new post, Julia Angwin and Jeff Larsen say
The findings were described in scholarly papers published or circulated over the past several months. Taken together, they represent the most far-reaching critique to date of the fairness of algorithms that seek to provide an objective measure of the likelihood a defendant will commit further crimes.
That’s true, but ‘algorithms’ and ‘objective’ don’t come into it. Any method of deciding who to release early has this problem, from judicial discretion in sentencing to parole boards to executive clemency. The only way around it is mandatory non-parole sentences, and even then you have to decide who gets charged with which crimes.
Fairness and transparency in machine learning are worth fighting for. They’re worth spending public money and political capital on. Part of the process must be deciding, with as much input from the affected groups as possible, what measures of fairness really matter to them. In the longer term, reducing the degree of disadvantage of, say, racial minorities should be the goal, and will automatically help with the decision problem. But a decision procedure that is ‘fair’ for disadvantaged groups both according to positive and negative predictive value and according to specificity and sensitivity isn’t worth fighting for, any more than a perpetual motion machine would be.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »
Very good approach to examining bias. Since we can’t comprehend the value of the learned model we have to inspect the output instead.
The danger is that right now we are at the stage where all our biases (intentional or otherwise) will be turned into an unmatabke training set and carried out for the foreseeable future.
A related talk to the problem:
https://www.ted.com/talks/zeynep_tufekci_machine_intelligence_makes_human_morals_more_important
7 years ago