Women and dementia risk
A Herald story headlined “Women face greater dementia risk – study” has been nominated for Stat of the Week, I think a bit unfairly. Still, perhaps it’s worth clarifying the points made in the nomination.
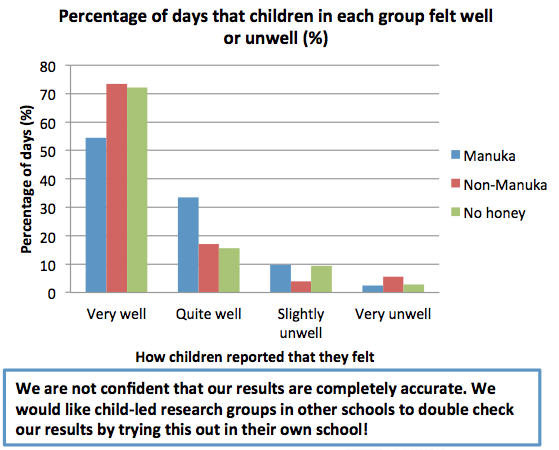
People diagnosed with dementia are more likely to be women, and the story mentions three reasons. The first is overwhelmingly the most important from the viewpoint of population statistics: dementia is primarily a disease of old people, the majority of whom are women because women live longer.
In addition, and importantly from the viewpoint of individual health, women are more likely to have diagnosed dementia than men in a given age range
European research has indicated that although at age 70, the prevalence of dementia is the same for men and women, it rapidly diverges in older age groups. By 85, women had a 40 per cent higher prevalence than men.
There could be many reasons for this. A recent research paper lists possibilities related to sex (differences in brain structure, impact of changes in hormones after menopause) and to gender (among current 85-year-olds, women tend to be less educated and less likely to have had intellectually demanding careers).
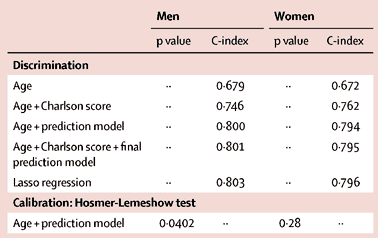
The third statistic mentioned in the Stat of the Week nomination was that “Women with Alzheimer’s disease (AD) pathology have a three-fold risk of being diagnosed with AD than men.” This is from research looking at people’s brains. Comparing people with similar amounts of apparent damage to their brains, women were more likely to be diagnosed with Alzheimer’s disease.
So, the differences in the summary statistics are because they are making different comparisons.
Statistical analysis of Alzheimer’s disease is complicated because the disease happens in the brain, where you can’t see. Definitive diagnosis and measurement of the biological disease process can only be done at autopsy. Practical clinical diagnosis is variable because dementia is a very late stage in the process, and different people take different amounts of neurological damage to get to that point.

{kind=link}