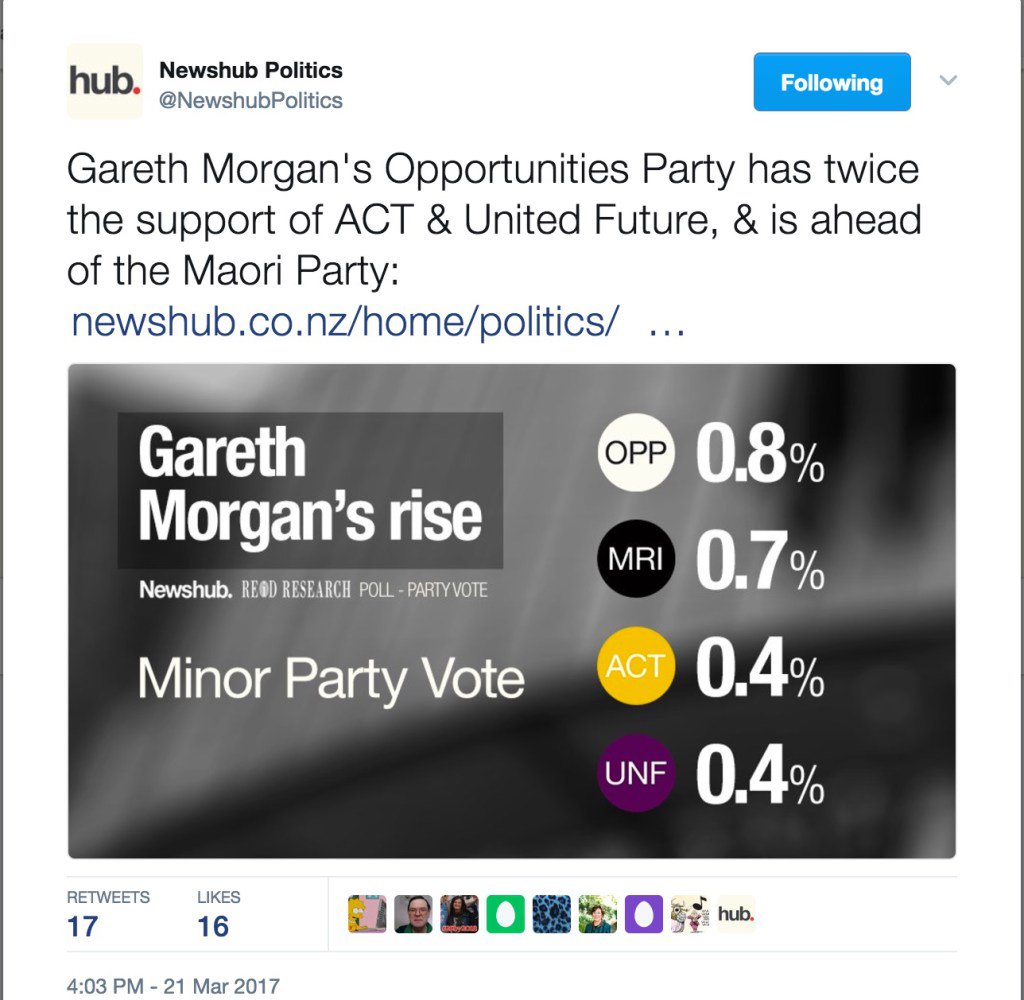
Technological progress in NZ polling
From a long story at stoppress.co.nz
For the first time ever, Newshub and Reid Research will conduct 25 percent of its polling via the internet. The remaining 75 percent of polling will continue to be collected via landline phone calls, with its sampling size of 1000 respondents and its margin of error of 3.1 percent remaining unchanged. The addition of internet polling—aided by Trace Research and its director Andrew Zhu—will aim to enhance access to 18-35-year-olds, as well as better reflect the declining use of landlines in New Zealand.
This is probably a good thing, not just because it’s getting harder to sample people. Relying on landlines leads people who don’t understand polling to assume that, say, the Greens will do much better in the election than in the polls because their voters are younger. And they don’t.
The downside of polling over the internet is it’s much harder to tell from outside if someone is doing a reasonable job of it. From the position of a Newshub viewer, it may be hard even to distinguish bogus online clicky polls from serious internet-based opinion research. So it’s important that Trace Research gets this right, and that Newshub is careful about describing different sorts of internet surveys.
As Patrick Gower says in the story
“The interpretation of data by the media is crucial. You can have this methodology that we’re using and have it be bang on and perfect, but I could be too loose with the way I analyse and present that data, and all that hard work can be undone by that. So in the end, it comes down to me and the other people who present it.”
It does. And it’s encouraging to see that stated explicitly.