Funding vs disease burden: two graphics
You have probably seen the graphic from vox.com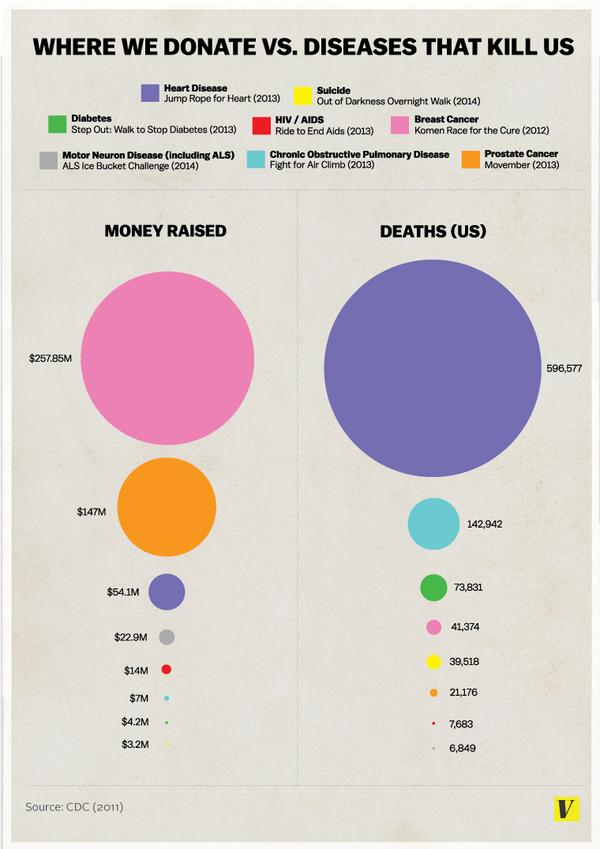
There are several things wrong with it. From a graphics point of view it doesn’t make any of the relevant comparisons easy. The diameter of the circle is proportional to the deaths or money, exaggerating the differences. And the donation data are basically wrong — the original story tries to make it clear that these are particular events, not all donations for a disease, but it’s the graph that is quoted.
For example, the graph lists $54 million for heart disease, based on the ‘Jump Rope for Heart’ fundraiser. According to Forbes magazine’s list of top charities, the American Heart Association actually received $511 million in private donations in the year to June 2012, almost ten times as much. Almost as much again came in grants for heart disease research from the National Institutes of Health.
There’s another graph I’ve seen on Twitter, which shows what could have been done to make the comparisons clearer:
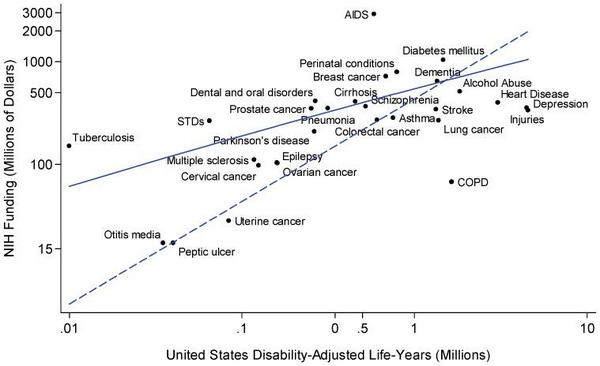
It’s limited, because it only shows government funding, not private charity, but it shows the relationship between funding and the aggregate loss of health and life for a wide range of diseases.
There are a few outliers, and some of them are for interesting reasons. Tuberculosis is not currently a major health problem in the US, but it is in other countries, and there’s a real risk that it could spread to the US. AIDS is highly funded partly because of successful lobbying, partly because it — like TB — is a foreign-aid issue, and partly because it has been scientifically rewarding and interesting. COPD and lung cancer are going to become much less common in the future, as the victims of the century-long smoking epidemic die off.
Depression and injuries, though?
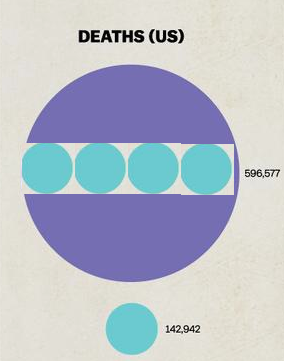
Update: here’s how distorted the areas are: the purple number is about 4.2 times the blue number
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »