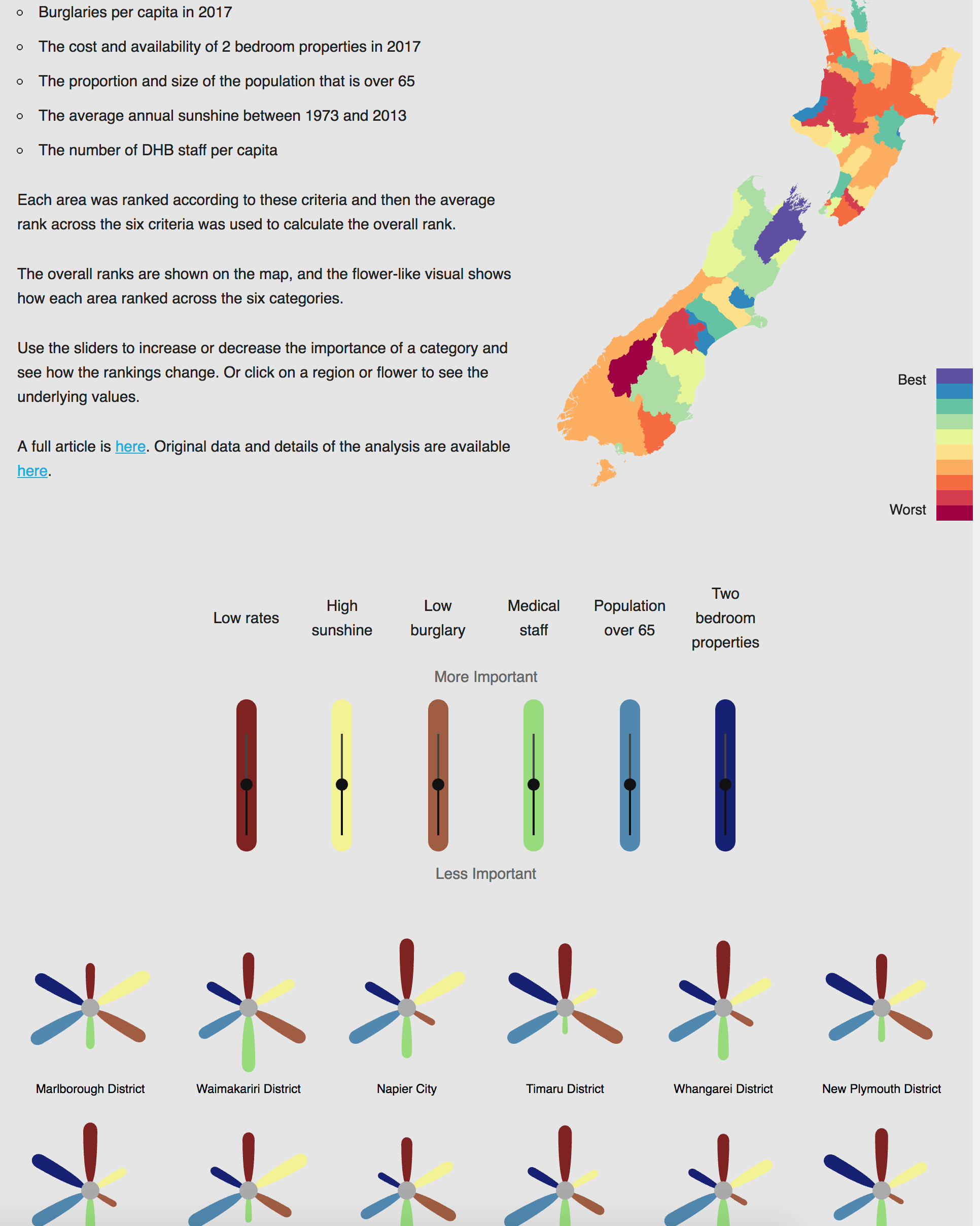
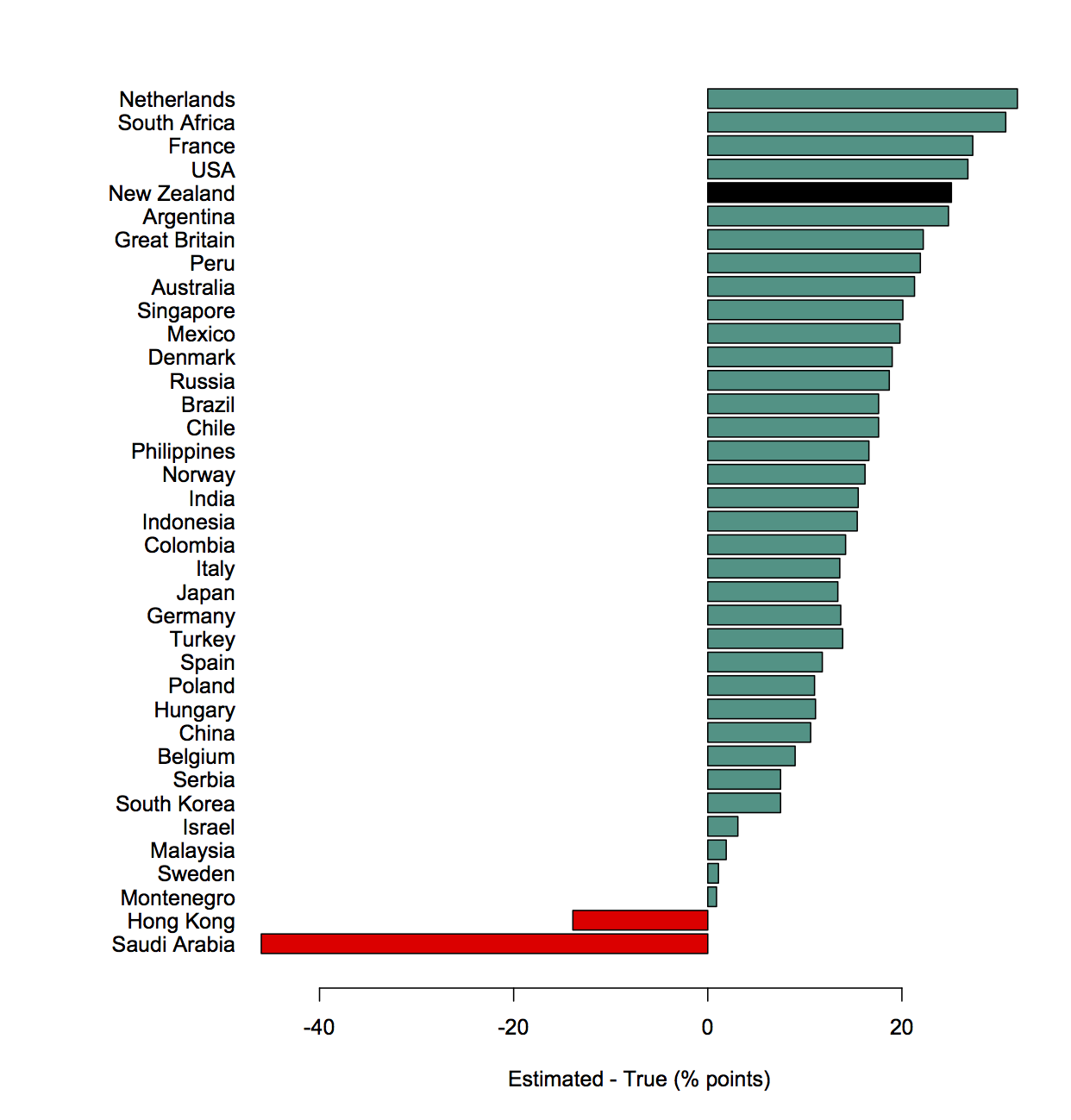
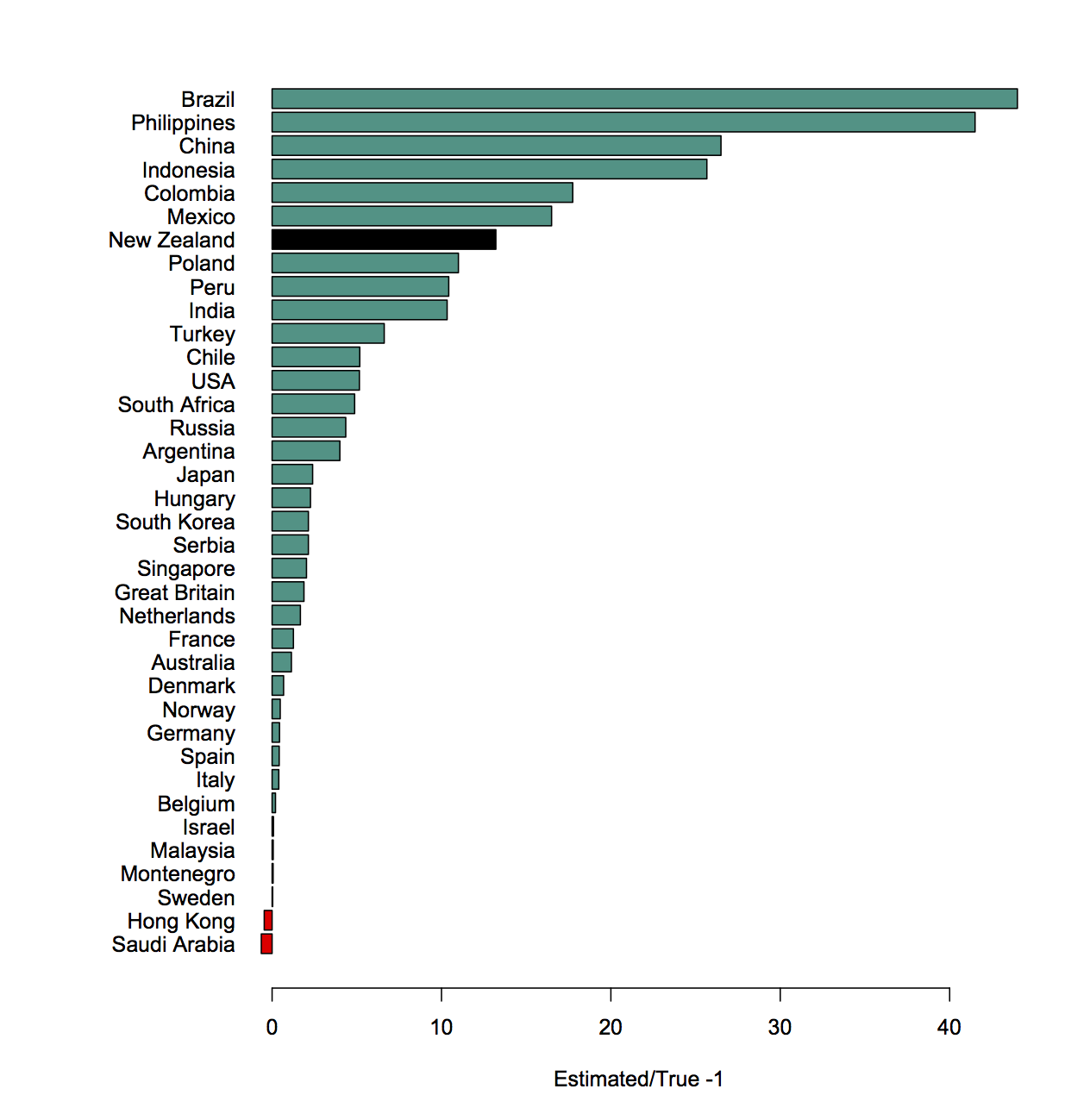
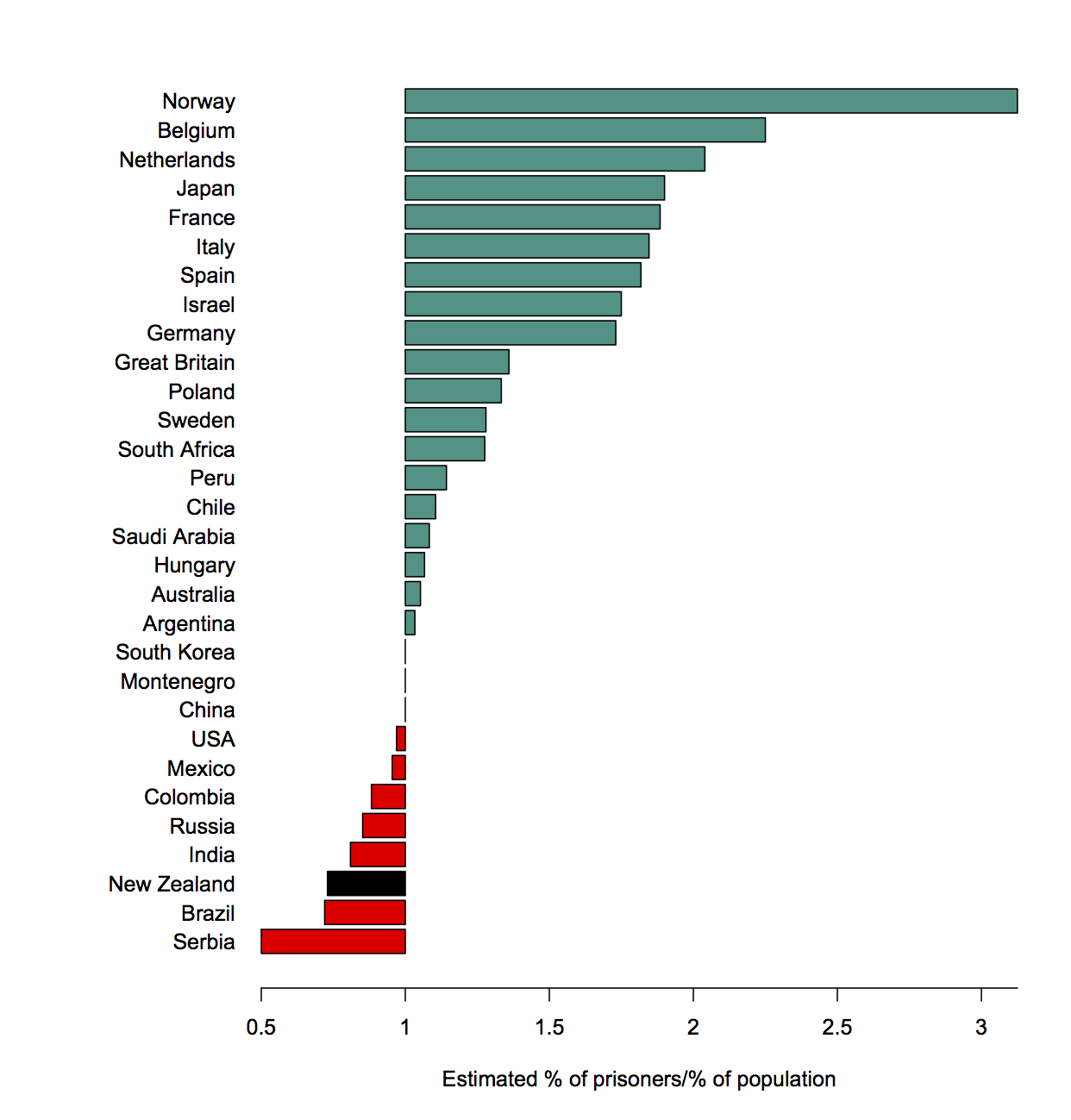
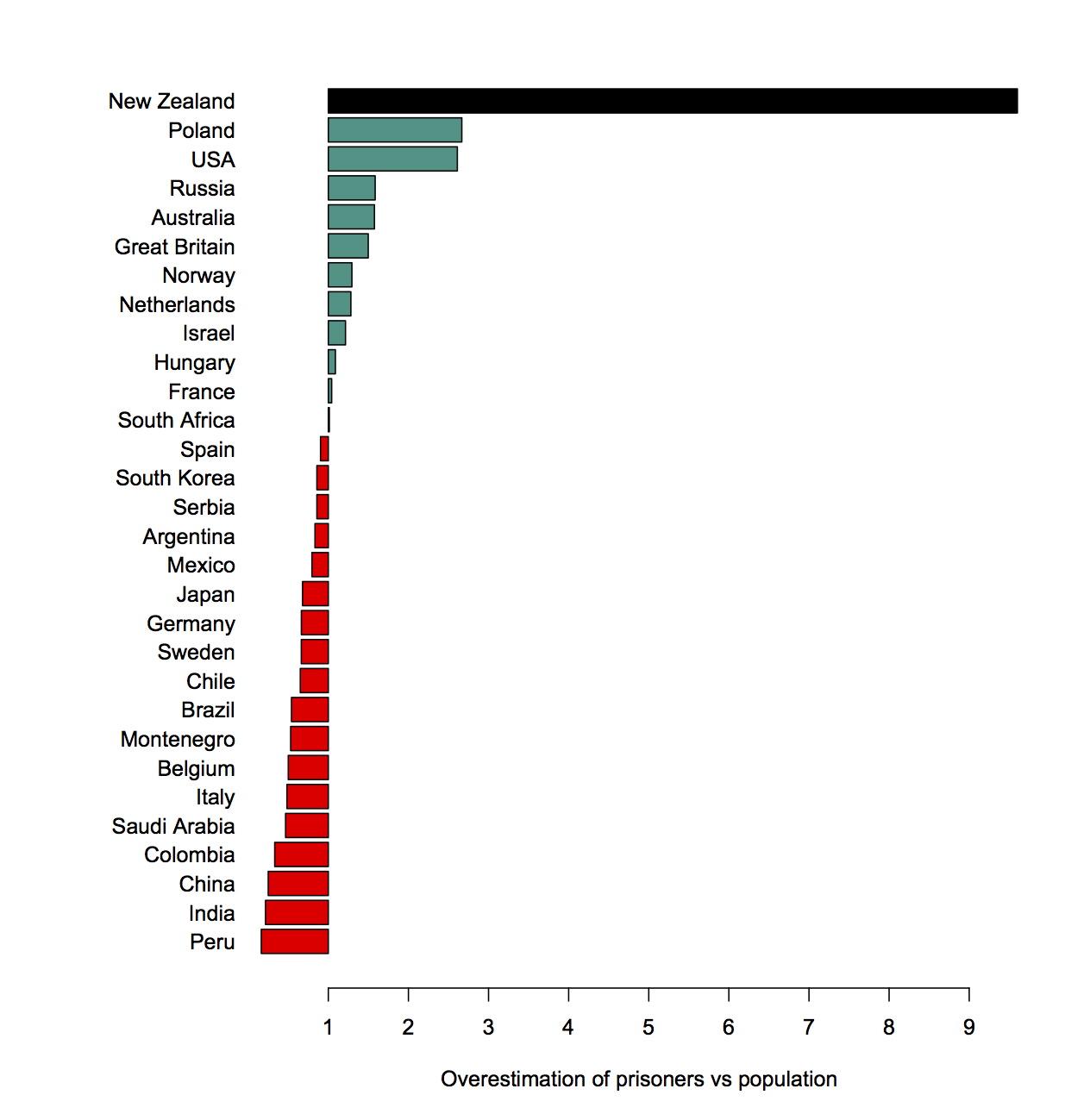
Meet Yiwen He, Statistics Summer Scholar
Every summer, the Department of Statistics offers scholarships to high-achieving students so they can work with staff on real-world projects. Yiwen, below, is working with Professor Chris Wild on iNZight, the free data visualisation and analysis software he developed.

Yiwen is doing a conjoint BSc and BCom majoring in Statistics, Mathematics and Finance at the University of Auckland. She’s from China, and moved here seven years ago.
Yiwen is working on the Department of Statistics-based data analysis package iNZight.
This is a free, R-based environment started by statistics education expert Professor Chris Wild to help high-school students quickly and easily explore data and understand some statistical ideas.
However, iNZight has grown, and now extends to multivariable graphics, time series, and generalised linear modelling, including modelling of data from complex surveys. It is available in web and desktop versions.
As iNZight has expanded, it has needed tweaking and tidying, and Yiwen is working on how it copes with incoming data that has date and time fields telling us when something happened. “These data are most likely to be in non-standard form, meaning our computing software cannot recognise and get useful information from it,” she explains.
Yiwen has been working with the iNZight team to develop functions to convert raw dates and times data to a standard format that iNZight can recognise, and extract desired components from a dates-and-times variable. “If we are able to automate how dates and times are handled by our computing software, we can plot dates and times together with our observations.”
Yiwen is finding the work stimulating and fun, “since we get to do things that are more practical, and it is exciting to see how the functions you build actually work on various data sets. And since we are given plenty of time in the project, it really encourages you to explore what is out there and extend your knowledge to more advanced coding stuff.”
High-achieving students like are a critical part of the development of iNZight, says Chris Wild. “It’s a student-driven project, so most of the big-scale changes occur over the New Zealand summer period. At other times, we mostly work on small changes and bug fixes.”
+ For general information on University of Auckland summer scholarships, click here.
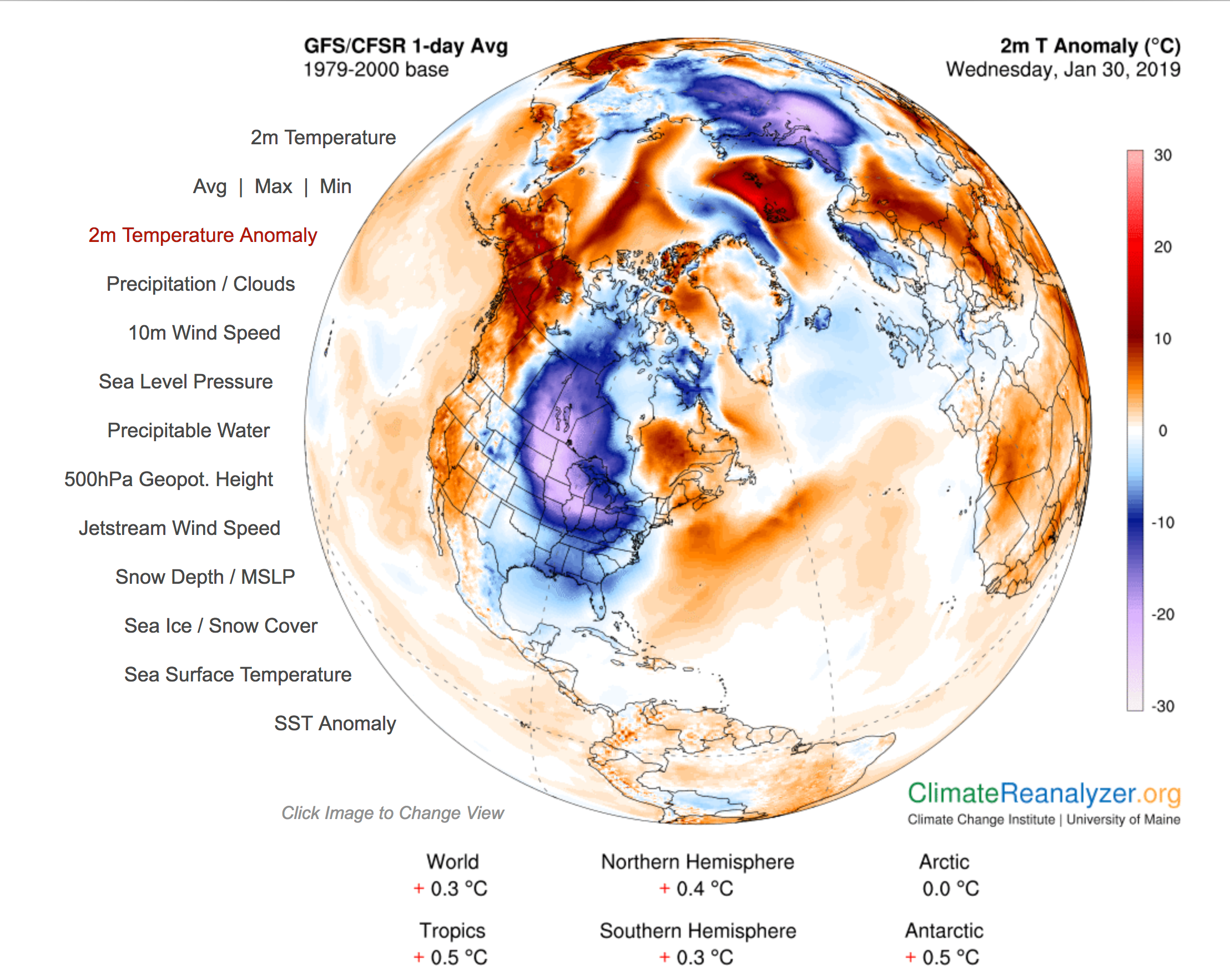

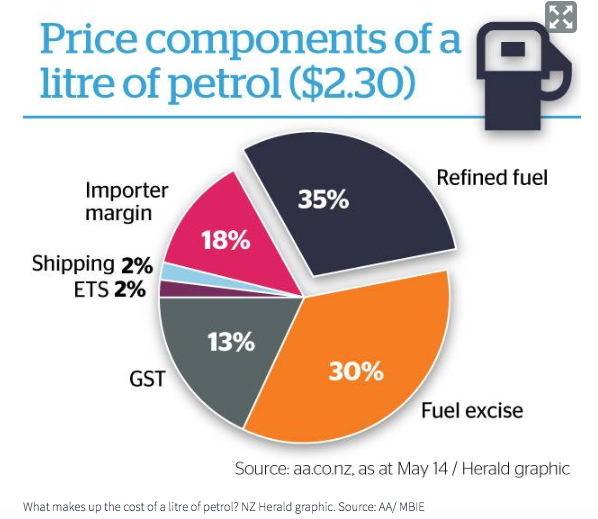
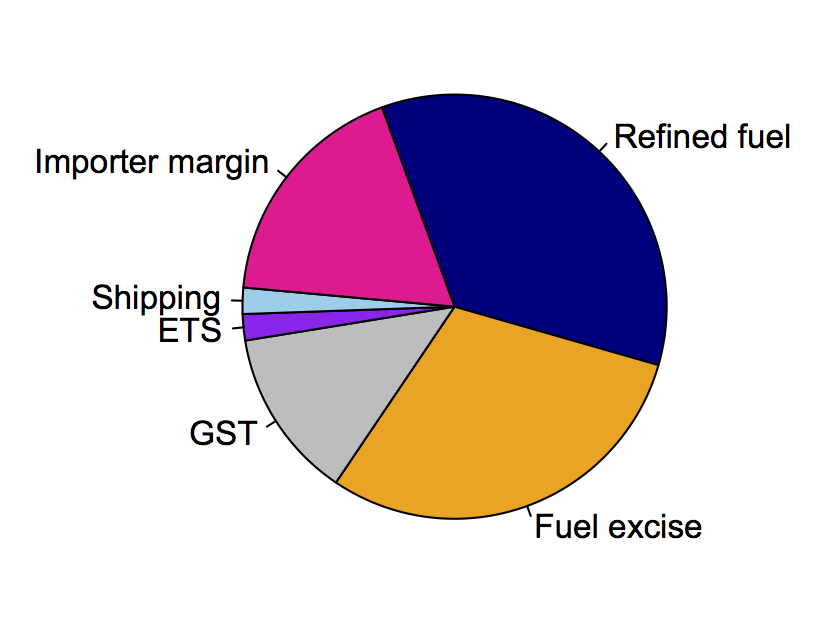
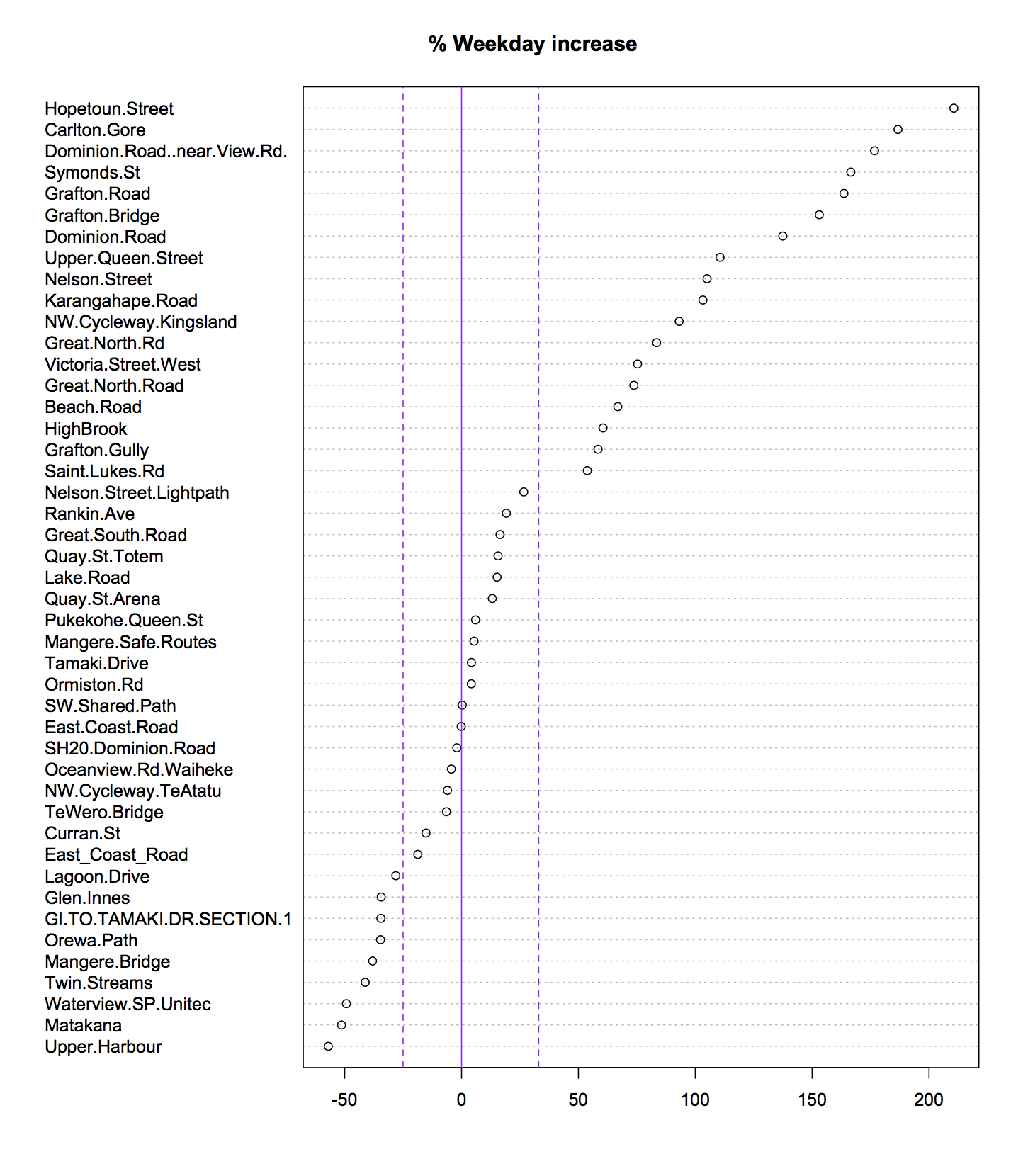
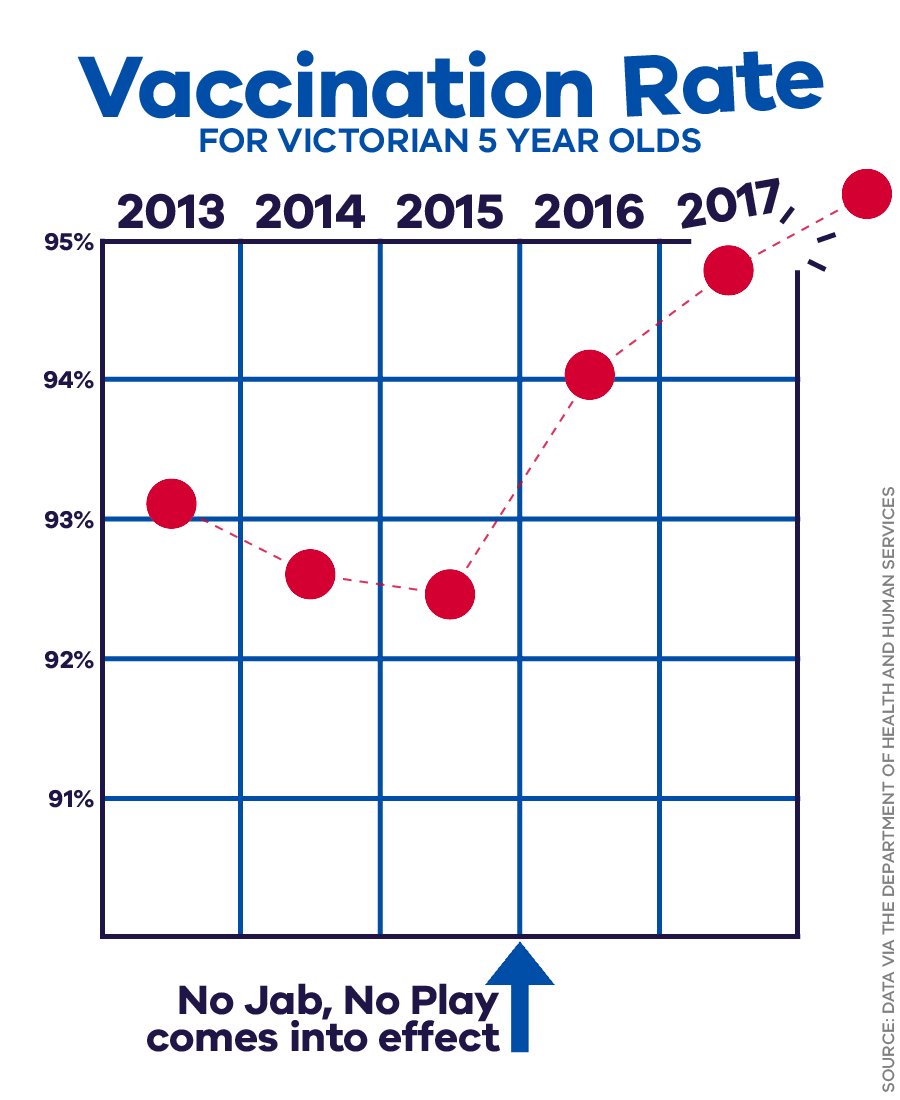
 tion.
tion. Auckland (left) will embark on a daring statistical graphics journey featuring the BrailleR package for visually-impaired users, high-performance computing, te reo, and XKCD.
Auckland (left) will embark on a daring statistical graphics journey featuring the BrailleR package for visually-impaired users, high-performance computing, te reo, and XKCD.  Professor in the Department of Statistics at the University of Auckland. Ross, along with Robert Gentleman, co-created R – a statistical programming language now used by the majority of the world’s practicing statisticians. It is hard to over-emphasise the importance of Ross’s contribution to our field, so we named this lecture series in his honour to recognise his work and contributions to our field in perpetuity.
Professor in the Department of Statistics at the University of Auckland. Ross, along with Robert Gentleman, co-created R – a statistical programming language now used by the majority of the world’s practicing statisticians. It is hard to over-emphasise the importance of Ross’s contribution to our field, so we named this lecture series in his honour to recognise his work and contributions to our field in perpetuity.