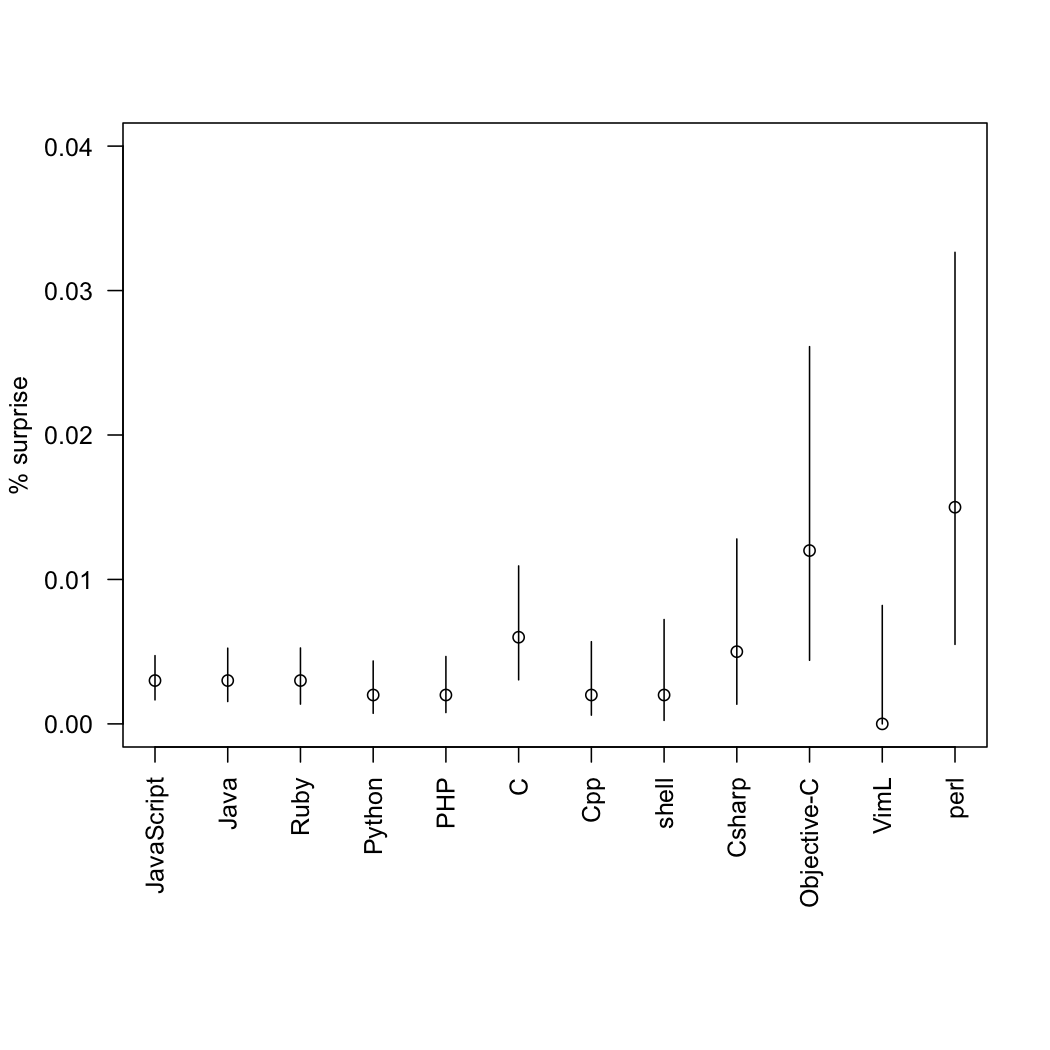
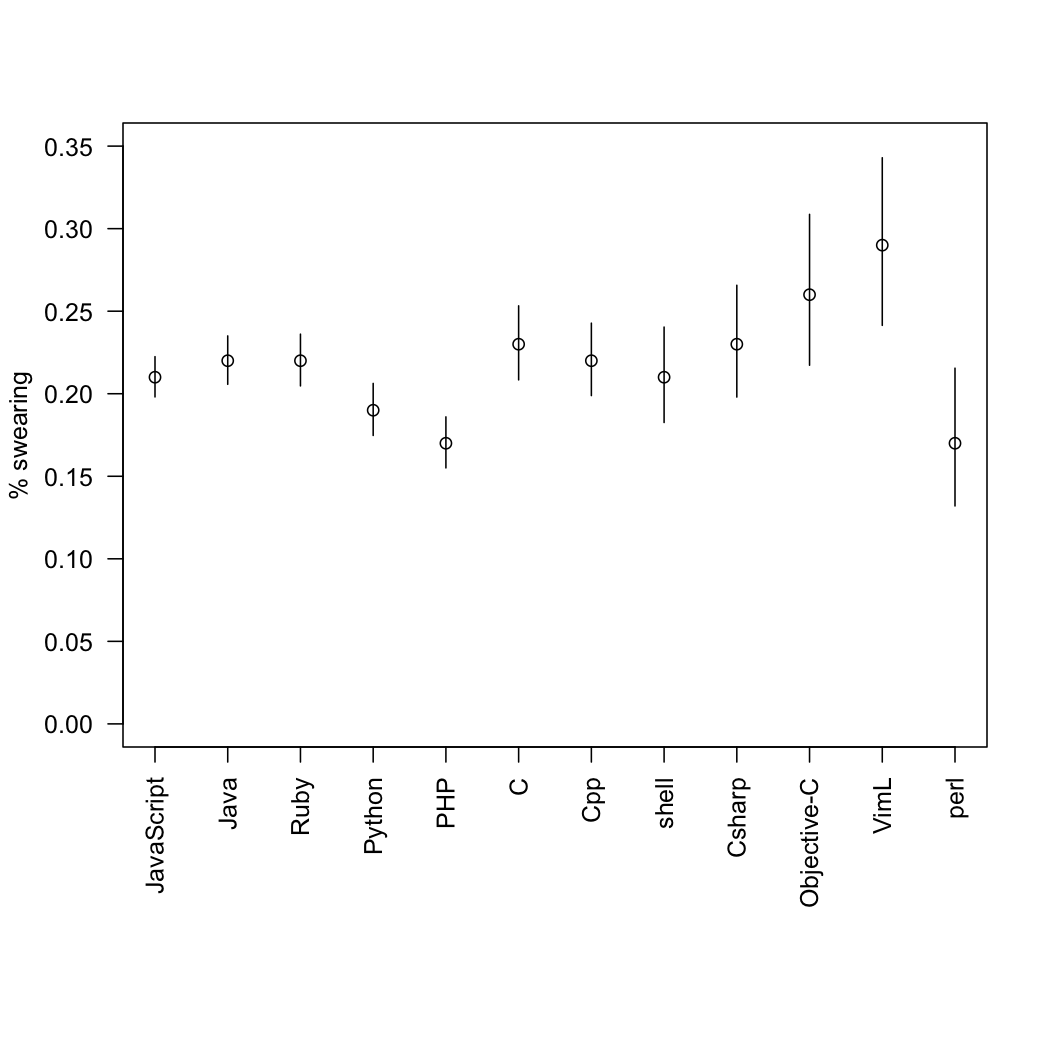
From the Guardian, some time ago
Jeremy Clarkson had a point – and that’s not something you hear me say every day (indeed, any day) – when in a recent Sun column he challenged the scientists […] who had described a slab of ice that had broken away from Antarctica as “the size of Luxembourg”.
“I’m sorry but Luxembourg is meaningless,” said Clarkson, pointing out that the standard units of measurement in the UK are double-decker London buses, football pitches and Wales. He could have added the Isle of Wight, Olympic-sized swimming pools and Wembley stadiums to the list.
These journalist units of measurements are useful only to the extent that they are more familiar and easily understood than the actual numbers.
From The Conversation, more recently, David Holmes begins
The planet is building up heat at the equivalent of four Hiroshima bombs worth of energy every second. And 90% of that heat is going into the oceans.
This image comes originally from John Cook, who writes
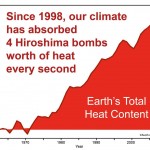
So I suggest a sticky way to communicate global warming is to express it in units of Hiroshima bombs worth of heat. This ticks all the sticky boxes:
- It’s simple – nothing communicates a lot of heat like an A-bomb.
- It’s unexpected – whenever I explain this to audiences, their eyes turn into saucers. Almost noone realises just how much heat our climate system is accumulating.
- It’s concrete – nobody has trouble conceptualising an A-bomb. Well, much of the younger generation don’t know about Hiroshima – when I test-drived this metaphor on my teenage daughter, she asked “what’s Hiroshima?”. But it’s easily recommunicated as an atomic bomb.
- It tells a story – the idea that second after second, day after day, the greenhouse effect continues to blaze away and our planet continues to build up heat.
-
The only downside of this metaphor is it is emotional – the Hiroshima bomb does come with a lot of baggage. However, this metaphor isn’t used because it’s scary – it’s simply about communicating the sheer amount of heat that our climate is accumulating. I’ve yet to encounter a stickier way of communicating the scale of the planet’s energy imbalance.
I think he’s wrong about the downside. The real downside is that the image of Hiroshima has nothing to do with heat production. The Hiroshima bomb was important because it killed lots of people, many of them civilians, ended the war, and ushered in the age of nuclear weapons where a small number of military or political leaders had the ability to destroy industrial civilisation and kill the majority of our species (which nearly happened, 30 years ago today).
If we set off four Hiroshima-scale bombs per second, global warming would become a relatively unimportant side issue — and in fact, nuclear weapons are much more widely associated with nuclear winter.
You could also invoke public health concerns and describe the heat accumulation as equivalent to everyone in the world smoking seven cigarettes per second (1185 cal/cig: data). That would be wrong in the same ways.