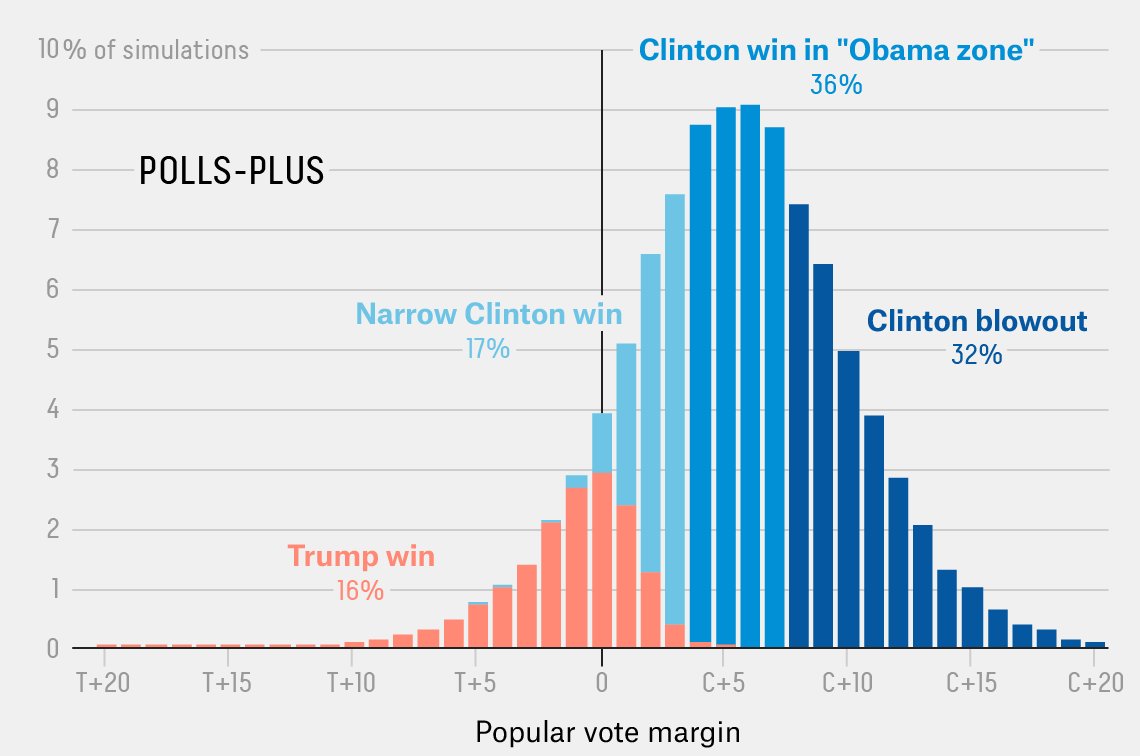
Prediction is hard — especially, as the Danish proverb says, when it comes to the future. In the Rugby World Cup we had psychic meerkats. For the US elections the new bogus prediction trend is Halloween masks: allegedly, more masks are sold with the face of the candidate who goes on to win.
The first question with a claim like this one, especially given some of the people making it, is whether the historical claim is true. In this case it’s true-ish. The claim was made before the 2012 election, and while the data aren’t comprehensive, they are from the same big chain of stores each year. From 1980 to 2012, the mask rule has predicted the eventual winner of the presidency. That’s actually an argument against it.
If there’s more to the mask sales than there is to psychic meerkats, it would have to be as a prediction of the popular vote — you’d need data from individual states to predict the weird US Electoral College. But if the mask rule got the 2000 election right, it must have got the popular vote wrong that year — George W. Bush won the electoral college, but lost the popular vote to Al Gore. From that point of view, we’re looking at 8 out of 9.
More importantly, 9 out of 9 isn’t all that impressive. Suppose you got your predictions by flipping a coin. Your chance of getting either all heads for the Republican wins or all heads for the Democratic wins is 1 in 256, increasing to 1 in 128 if you’re allowed to choose which way to treat the 2000 election. The chance of getting 8 of 9 agreement is much better: about 1 in 13. If only one in a million people in the US had tried coming up with just one prediction rule each, you’d expect someone to get it perfect and dozens to get it nearly right.
Given these odds, it wouldn’t be surprising if, say, a US professional sports team had results agreeing with the Presidential results — and in fact, there was a rule based on the results for the Washington Redskins football team that worked from 1940 to 2000, was fudged to work in 2004, and then failed completely in 2012. That’s 17/19 correct, but since the rule was first publicised in the run-up to the 2000 election, it’s 2/4 correct in actual use.
If you’re allowed to combine multiple variables it gets even easier to find rules. With anything from basic linear regression to a neural network you’d expect to get perfect prediction from five unrelated variables. Even restricting the models to be simple doesn’t help much. I downloaded some OECD data on national GDP for various countries, and found that since 1980 the Republicans have won the popular vote precisely in years when the GDP of Sweden increased more than the GDP of Norway.
My advice is to stick with the psychic meerkats for entertainment and the opinion poll aggregators or the betting markets for prediction.