Not all algorithms wear computers
Via maths teacher Twitter, two graphs, from the economics PhD research of Cody Tuttle, showing data from the United States Sentencing Commission on recorded drug amounts in federal drug cases.
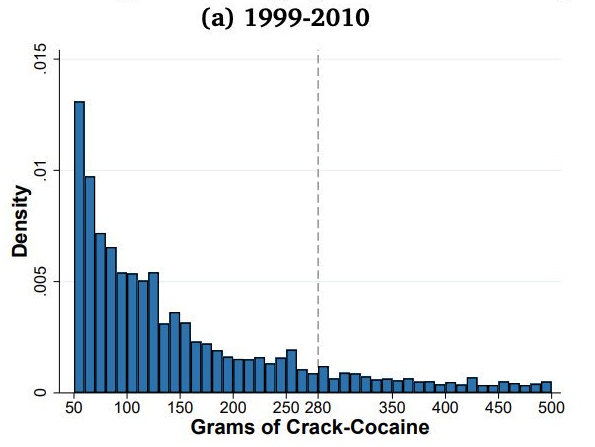
The first one shows amounts of crack cocaine 1990-2010
The second shows crack cocaine for the years 2011-2015
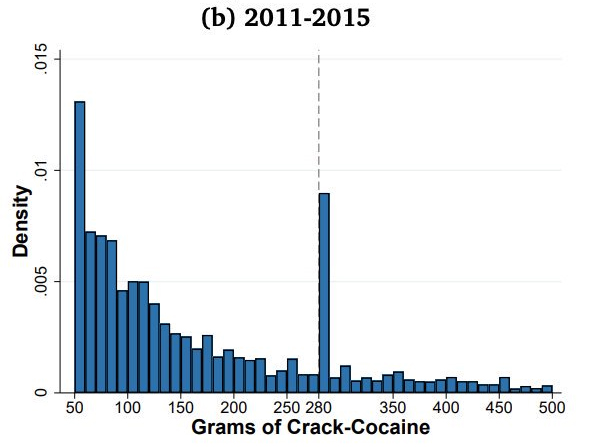
For some reason, people suddenly started getting caught with 280g of crack in 2011. Now, 280g is a rounder number than it looks — it’s 20 times 14g, or in other words, 10 ounces. Even so, you’d wonder why 10oz loads of cocaine suddenly started being popular.
It turns out that there was a change in the law. Up to 2010, a relic of the ‘war on drugs’ period meant there was a mandatory 10-year minimum sentence for more than 50g. From 2011, the threshold for the mandatory minimum was 280g. Suddenly, the proportion of people convicted of having 280-290g shot up. Further graphs and analyses show that the increase was much more pronounced for Black and Hispanic defendants than White.
Interestingly, the paper says “However, the data on drug seizures made by local and federal agencies do not show increased bunching at 280g after 2010.” The conclusion reached in the analysis is that a substantial minority of prosecutors, who have some discretion in deciding what quantity of drugs to list in the charges, misused this discretion.
The analysis is a good example of the sort of auditing you’d like for high-stakes computer algorithms, and it shows how you can bias the outputs of a decision-making system (such as the court) by biasing the data you feed it.
One of the advantages of computerised algorithms is that this sort of auditing is much easier (in principle). It’s because you can’t force the US Federal court system to run on your choice of simulated data that you need to rely on ‘natural experiments’ like this one.
Thomas Lumley (@tslumley) is Professor of Biostatistics at the University of Auckland. His research interests include semiparametric models, survey sampling, statistical computing, foundations of statistics, and whatever methodological problems his medical collaborators come up with. He also blogs at Biased and Inefficient See all posts by Thomas Lumley »