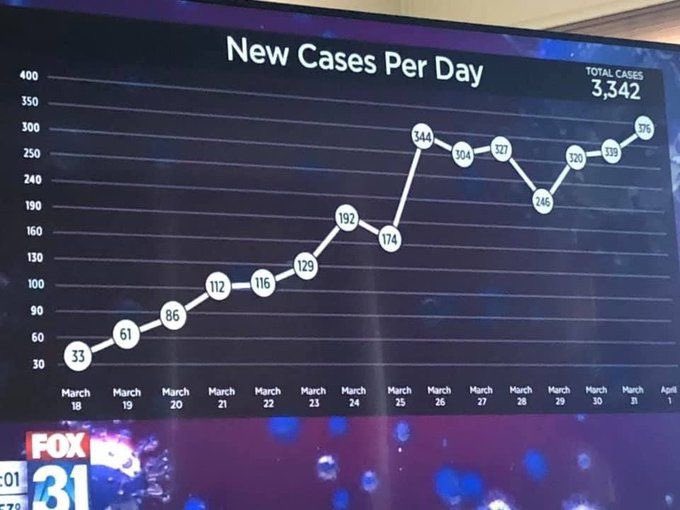
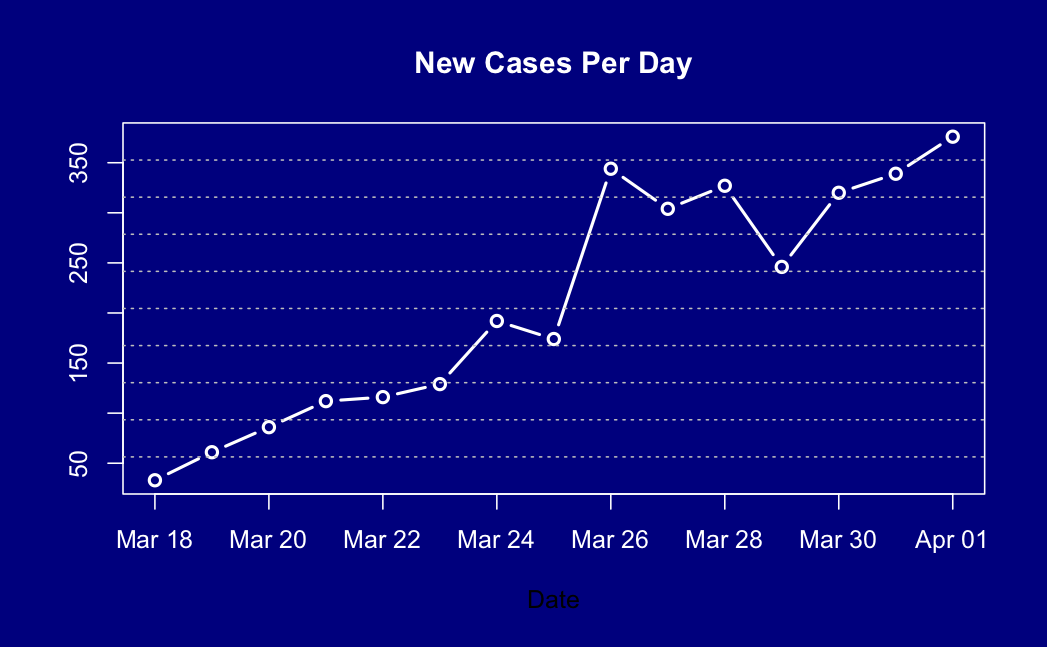
As promised, a second ‘prevalence’ post, this time on test accuracy.
In any medical diagnostic or screening setting, what we know is the number of positive and negative tests. What we want to know is the number of people with and without the condition. It’s easy to slip into talking about these as if they’re the same, but they aren’t.
For the coronavirus, we have two basic sorts of test. There are ‘PCR’ tests, which is what everyone had been using. And there are ‘antibody’ tests, which are new.
The PCR tests measure the presence of the virus. They transcribe the genetic material of the virus from RNA to DNA, and then use DNA copying enzymes to amplify it billions of times; the ‘polymerase chain reaction’. After amplification, there’s enough of the genetic sequence that fluorescent dyes attached to it or to the input materials can produce measurable light.
The copying looks for a unique, fairly short, genetic sequence that’s present in the new coronavirus, but not in the SARS or MERS viruses, or the four coronaviruses that cause common colds (in fact, usually more than one genetic sequence, plus a ‘positive control’ that makes sure the process is working, plus a ‘negative control’ that doesn’t have any RNA). Because of the fidelity of DNA replication, the technical ‘assay error’ of the PCR test is so close to zero as makes no difference: a few copies of the virus are enough for a positive result, and it’s almost impossible to get a positive result without any virus.
Unfortunately, the real-world diagnostic error isn’t quite that good. The false positive rate is still basically zero, given good lab practice; you can’t get a positive test without viral RNA from some source. The false negative rate can be appreciable, because the test doesn’t ask if there’s virus somewhere in your system; it asks if there’s virus on the swab. In early COViD-19 disease, the best way to grab some virus is to stick a swab almost far enough up your nose to do brain surgery, and twist it around a bit. More often than not, this will pick up some virus. But if you get tested too early, there might not be enough virus, and if you get tested too late the infection might have relocated to your chest.
So how good is the PCR test in practice? Well, we don’t know for sure. It’s the best test we have, so there isn’t a ‘true answer’ to compare it to. However, a study that looked at tests using multiple ways of extracting a sample, suggest the sensitivity of the test is 65%: if you have early-stage COViD-19, you’ve got about a two in three chance of testing positive. There’s a lot of uncertainty around the exact value; fortunately the exact value doesn’t matter all that much.
Antibody tests are new for coronavirus, but are familiar in other settings. Older HIV tests looked for antibodies to the virus, as do the initial tests for Hepatitis C (which are followed up by PCR). These antibody tests rely on the highly selective binding of antibodies to the antigens they detect. Because antibody tests detect your body’s reaction to the virus, a positive reaction takes time — at least a few days, maybe a week — and it stays around at least a short time after you recover. Antibody tests are amazingly accurate, but not quite as amazingly accurate as PCR. Everyone has exactly the same identifying genetic tags in their virus, but everyone makes slightly different antibodies to the virus. An antibody test is trying to pick up everyone’s diverse antibodies to the new coronavirus, but not pick up anyone’s antibodies to the nearly infinite diversity of other antigens in the world, including other coronaviruses. At any point in time, there’s a tradeoff: a test that picks up coronavirus antibodies more sensitively will also pick up more other things, and one that avoids reacting to other things will miss more coronavirus infections.
As I said above, the exact value of the false negative positive rate doesn’t matter that much when you’re estimating population prevalence. The false positive negative rate matters a lot. Suppose you have an antibody test with a false positive rate of 5%. For every 100 truly-negative people you test, there will be an average of 5 positive tests; for every 1000 people, 50 positive tests. In New Zealand, we’re sure the population prevalence is less than 1%, and I would expect it to be less than 0.1%. If you gave this test to 1000 people, there would be an average 50 positive results and maybe one or two true positives. It is very much an average, so if you got 53 positive tests you would have no idea whether that was five true positives or three or none at all. Even if the false positive rate were as low as 0.5%, you’d expect more false positives than true positives in New Zealand. And it’s worse than that: the error rates aren’t known accurately yet, so even if the manufacturer’s estimate was 0.5% false positives, it could easily be 1% or maybe even 2%.
There’s a new study out of Stanford (preprint) that tested 3330 people and found 50 positives. A helpful StatsChat reader posted a link to a review of this study. What I’m writing here agrees pretty closely with that review.
A rate of 50 positives out of 3330 healthy people is high: if true, it would imply COViD-19 was much more common and therefore much less serious than we thought. The researchers used a test that had given 2 positive results out of 401 samples known to be negative (because they were taken before the pandemic started). If the false positive rate was exactly 2/401 , you’d get 0.005×3330 false positives on average, or only about 17, leaving 33 true positives. But 2/401 is an estimate, with uncertainty. If we assume the known samples were otherwise perfectly representative, what we can be confident of with 2 positives out of 401 is only that the false positive rate is no greater than 1.5%. But 1.5% of 3330 is 50, so a false positive rate of 1.5% is already enough to explain the results! We don’t even have to worry if, say, the researchers chose this test from a range of competitors because it had the best supporting evidence and thereby introduced a bit of bias.
On top of that, the 3330 people were tested because they responded to Facebook ads. Because infection is rare, you don’t need to assume much self-selection of respondents to bias the prevalence estimate upwards. You might be surprised to see me say this, because yesterday I thought voluntary supermarket surveys were a pretty good idea. They are, but they will still have bias, which could be upwards or downwards. We wouldn’t use the results of a test in a few supermarkets to overturn the other evidence about disease severity; we want to use them to start finding undetected cases — any undetected cases.
Counting rare things is hard, and false positives are overwhelmingly more important than false negatives, which is currently a problem for antibody tests. PCR tests based on a swab are unpleasant for the person being tested and risky for the person holding the swab, but they are the best we have now. There might be other ways to use antibody tests, for example if true infections cluster more strongly within household than false positives, or if two tests with different characteristics can be combined, or if more accurate ones become available. But it’s not easy.