Poisson variation strikes again
What’s the best strategy if you want to have a perfect record betting on the rugby? Just bet once: that gives you a 50:50 chance.
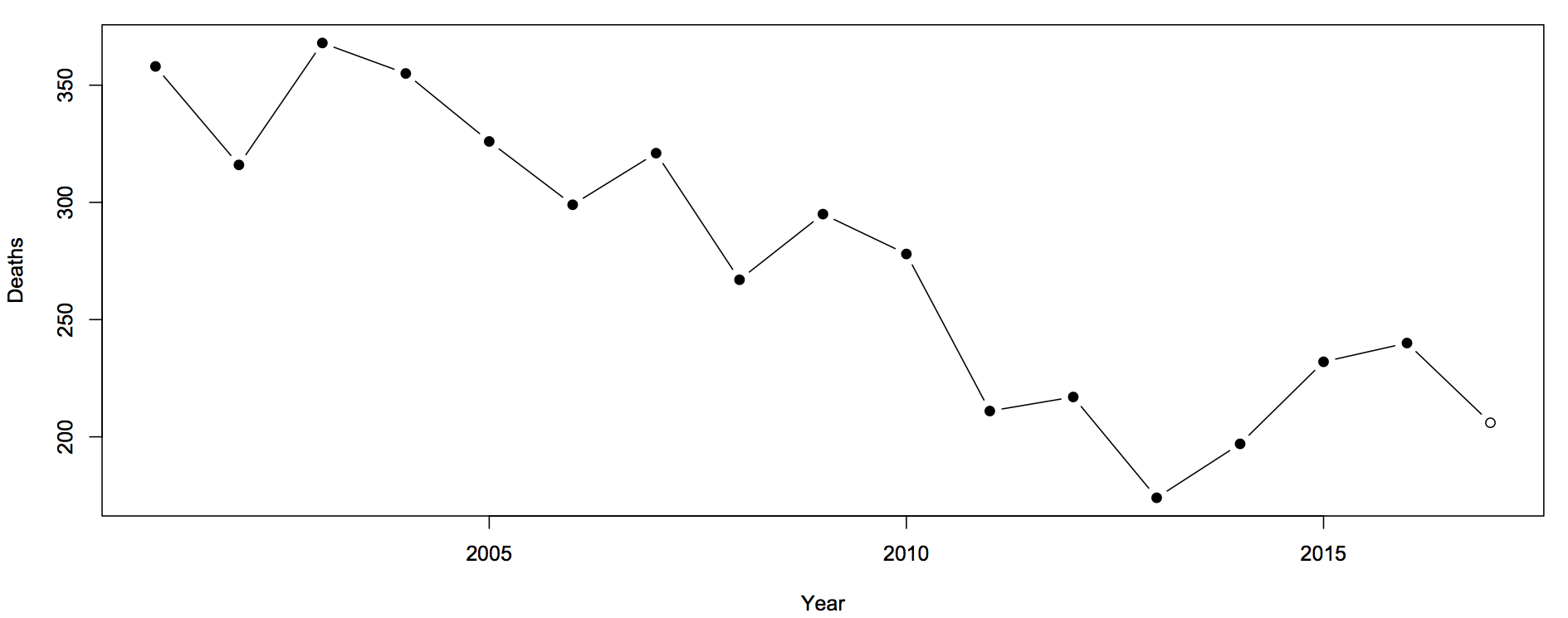
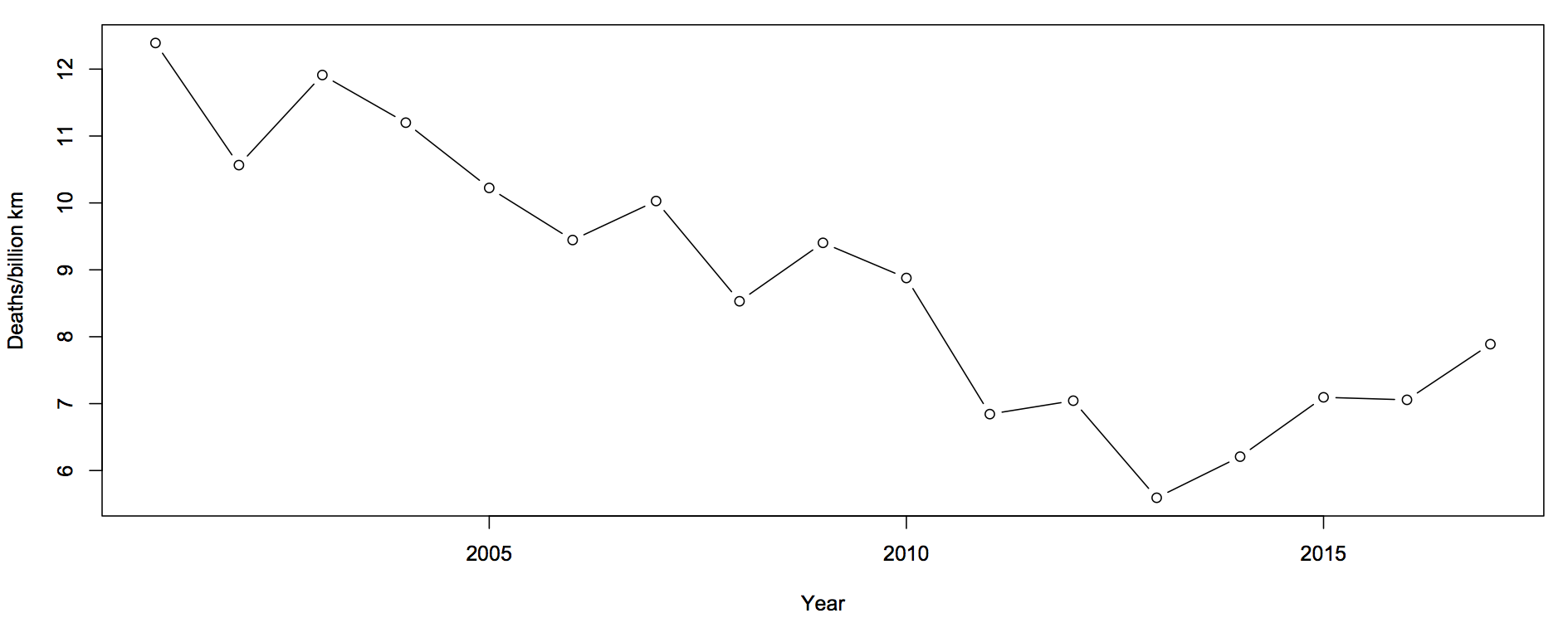
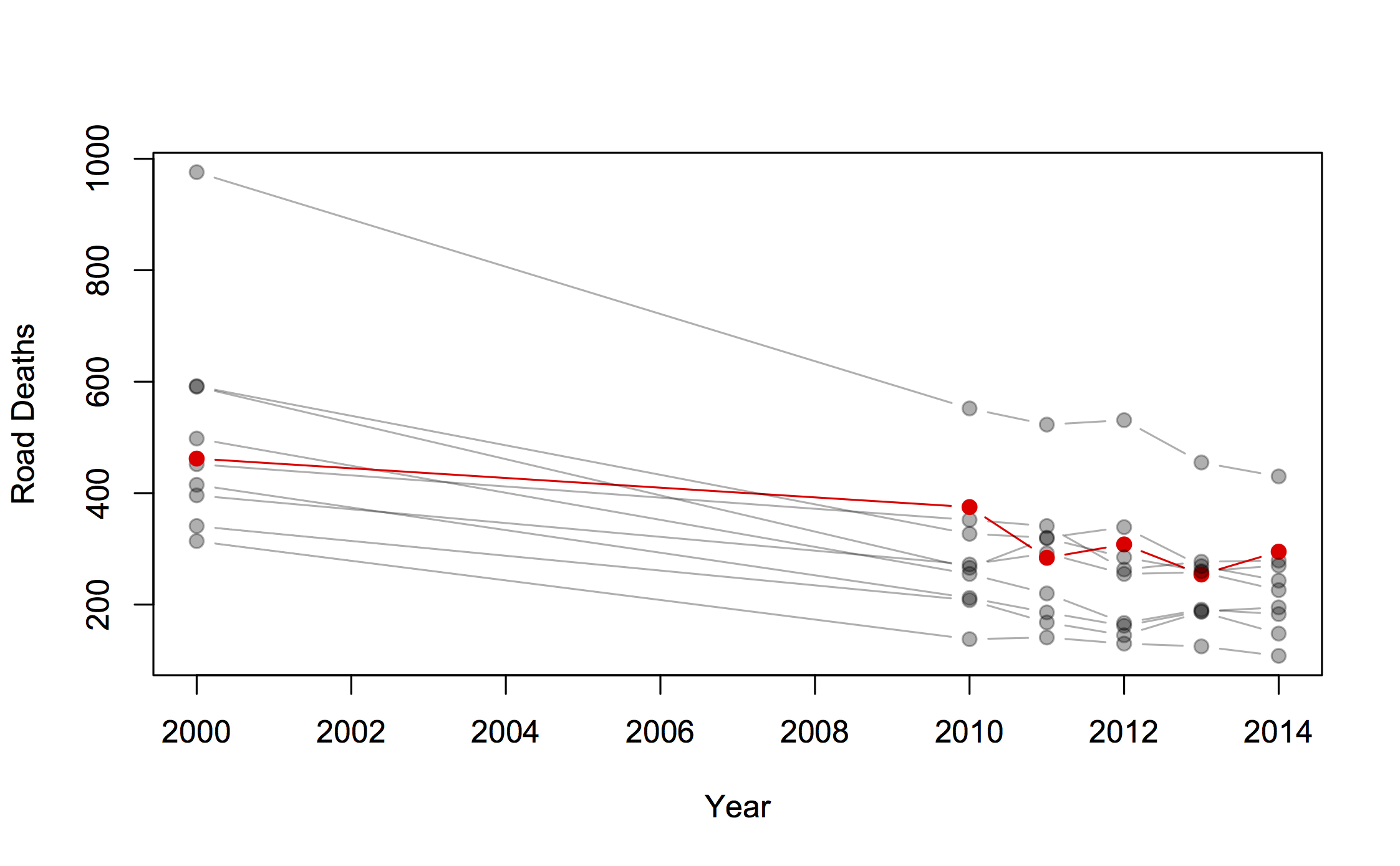
After national statistics on colorectal cancer were released in Britain, the charity Beating Bowel Cancer pointed out that there was a three-fold variation across local government areas in the death rate. They claimed that over 5,000 lives per year could be saved, presumably by adopting whatever practices were responsible for the lowest rates. Unfortunately, as UK blogger ‘plumbum’ noticed, the only distinctive factor about the lowest rates is shared by most of the highest rates: a small population, leading to large random variation.
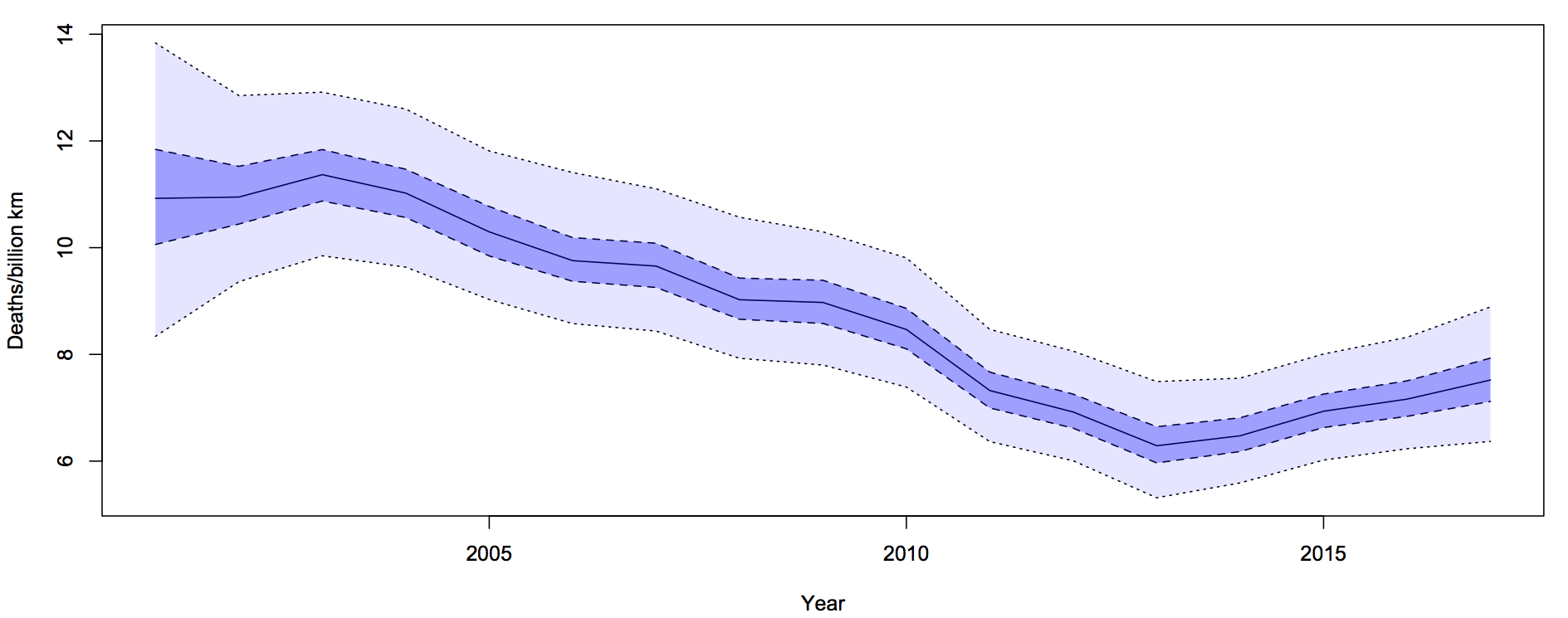
 His article was picked up by a number of other blogs interested in medicine and statistics, and Cambridge University professor David Speigelhalter suggested a funnel plot as a way of displaying the information.
His article was picked up by a number of other blogs interested in medicine and statistics, and Cambridge University professor David Speigelhalter suggested a funnel plot as a way of displaying the information.
A funnel plot has rates on the vertical axis and population size (or some other measure of information) on the horizontal axis, with the ‘funnel’ lines showing what level of variation would be expected just by chance.
The funnel plot (click to embiggen) makes clear what the tables and press releases do not: almost all districts fall inside the funnel, and vary only as much as would be expected by chance. There is just one clear exception: Glasgow City has a substantially higher rate, not explainable by chance.
Distinguishing random variation from real differences is critical if you want to understand cancer and alleviate the suffering it causes to victims and their families. Looking at the districts with the lowest death rates isn’t going to help, because there is nothing very special about them, but understanding what is different about Glasgow could be valuable both to the Glaswegians and to everyone else in Britain and even in the rest of the world.