Auckland is bigger than Wellington
There’s a long interactive in the Herald prompted by the 2000th Lotto draw, earlier this week. Among other interesting things, it has a graph of purporting to show the ‘luckiest’ regions
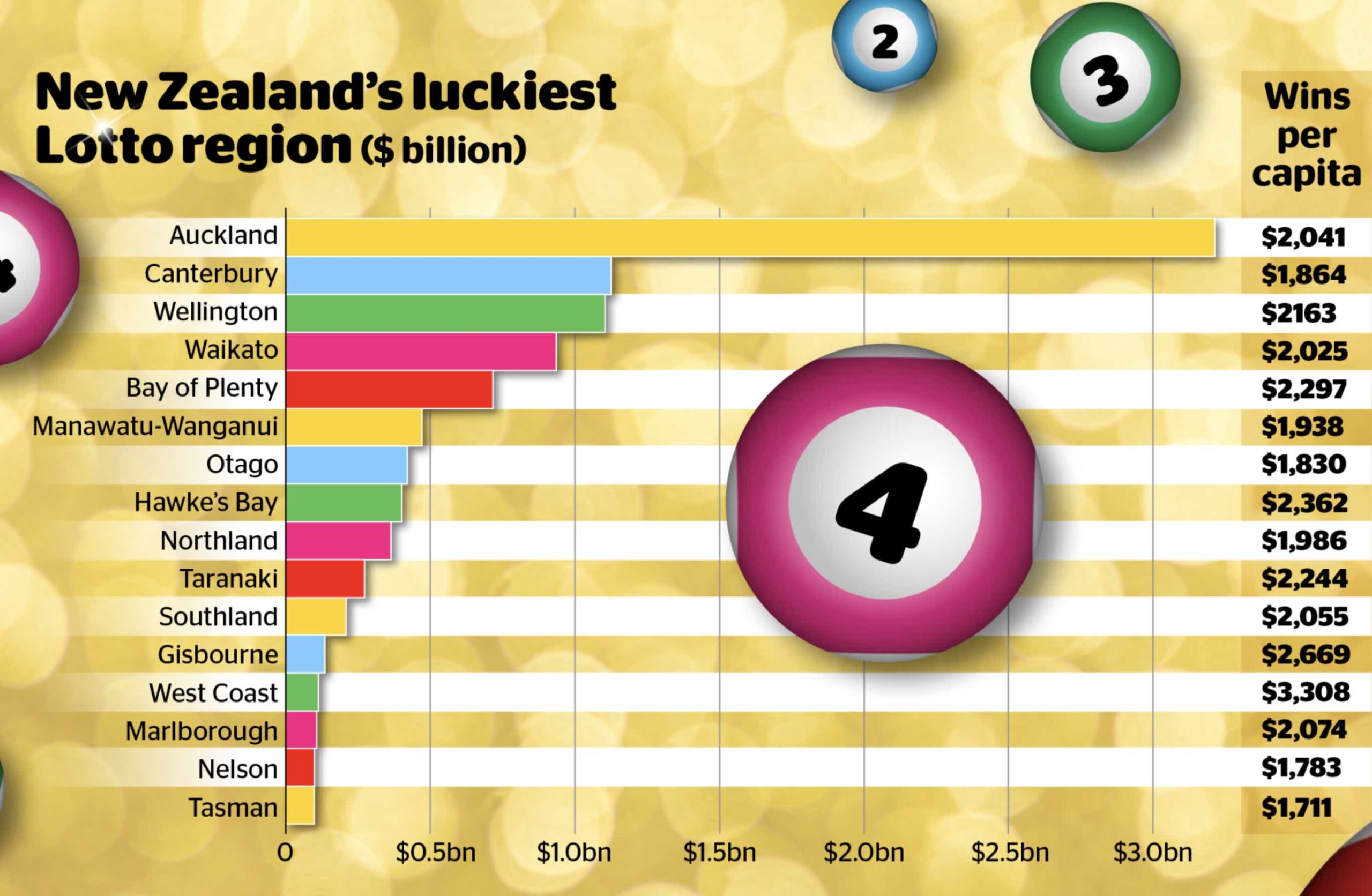
Aucklanders have won more money in Lotto prizes than any other region — roughly three times as much as either Canterbury or Wellington. By an amazing coincidence, Auckland has roughly three times the population of Canterbury or Wellington. The bar chart is only showing population. Auckland is not punching above its weight.
Wins per capita are over on the side, and are much less variable. Some of this will be that people in different regions play Lotto more or less ofter; some probably was luck. It’s possible that some variation is due to strategy — not variation in whether you win, but in how much.
Perhaps more importantly, the ‘wins per capita’ figure is gross winnings, not net winnings. Lotto NZ didn’t release details of expenditures, but 2000 draws is a long enough period of time that we can work with averages and get a rough estimate. As the Herald reports, about 55c in the dollar goes in prizes, so the gross winnings will average about 55% of revenue and the net winnings will average -45% of revenue, or -9/11 times gross winnings.
So: as an estimate over the past 2000 draws, the ‘luckiest’ NZ regions
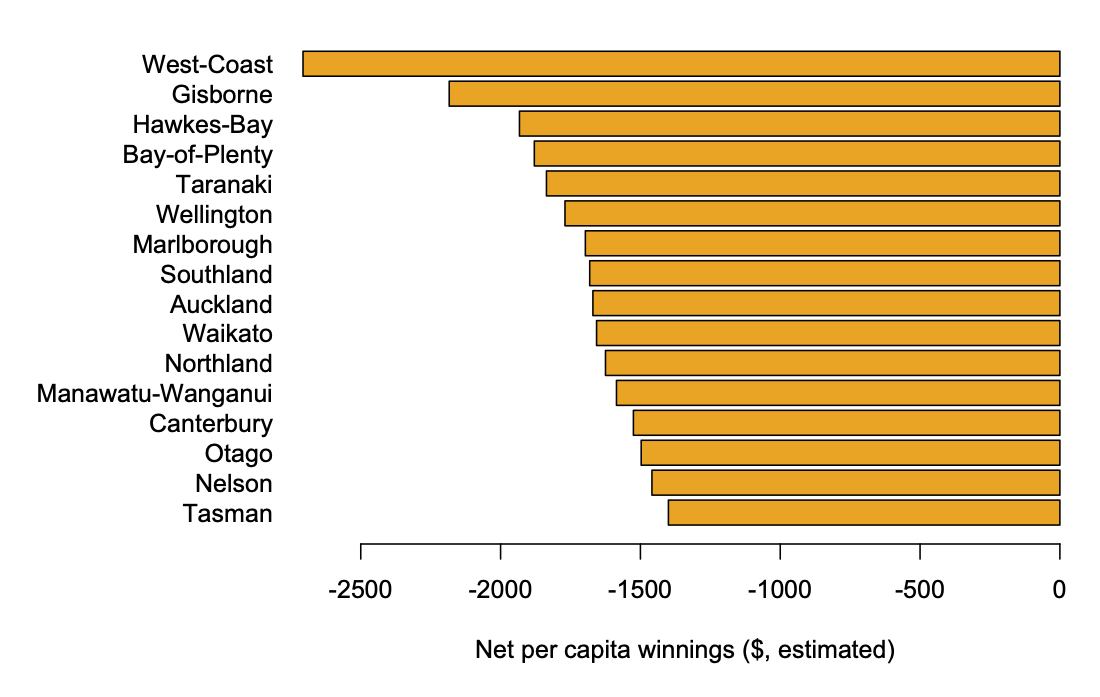
Some of the smaller regions are probably misrepresented here by good/bad luck — if Lotto NZ released actual data on revenue by region I’d be happy to do a more precise version