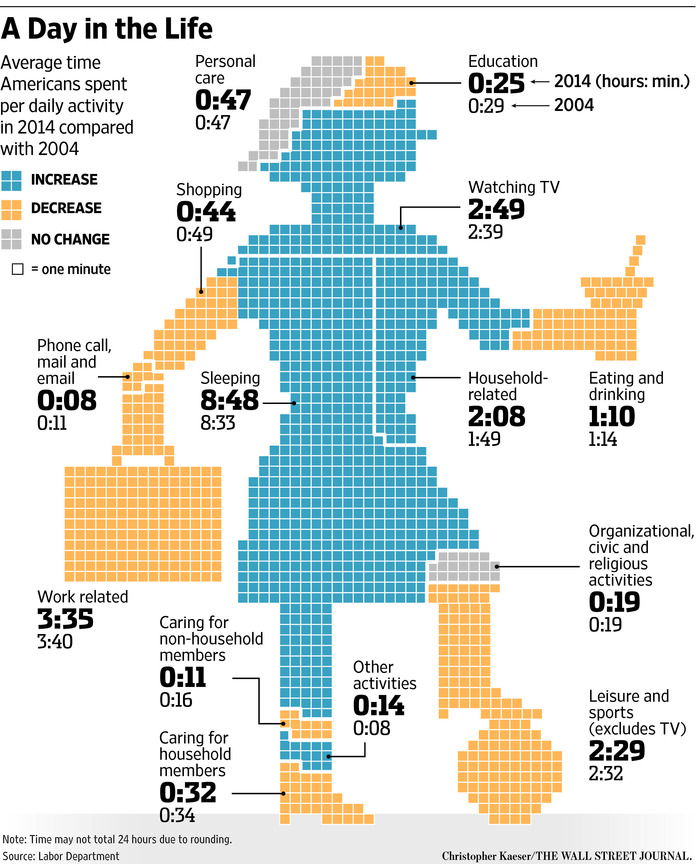
Targeting cancer treatments to specific genetic variants has certainly had successes with common mutations — the most well known example must be Herceptin for an important subset of breast cancer. Reasonably affordable genetic sequencing has the potential for finding specific, uncommon mutations in cancers where there isn’t a standard, approved drug.
Most good ideas in medicine don’t work, of course, so it’s important to see if this genetic sequencing really helps, and how much it costs. Ideally this would be in a randomised trial where patients are randomised to the best standard treatment or to genetically-targeted treatment. What we have so far is a comparison of disease progress for genetically-targeted treatment compared to a matched set of patients from the same clinic in previous years. Here’s a press release, and two abstracts from a scientific conference.
In 72 out of 243 patients whose disease had progressed despite standard treatment, the researchers found a mutation that suggested the patient would benefit from some drug they wouldn’t normally have got. The median time until these patients starting getting worse again was 23 weeks; in the historical patients it was 12 weeks.
The Boston Globe has an interesting story talking to researchers and a patient (though it gets some of the details wrong). The patient they interview had melanoma and got a drug approved for melanoma patients but only those with one specific mutation (since that’s where the drug was tested). Presumably, though the story doesn’t say, he had a different mutation in the same gene — that’s where the largest benefit of sequencing is likely to be.
An increase from 12 to 23 weeks isn’t terribly impressive, and it came at a cost of US$32000 — the abstract and press release say there wasn’t a cost increase, but that’s because they looked at cost per week, not total cost. It’s not nothing, though; it’s probably large enough that a clinical trial makes sense and small enough that a trial is still ethical and feasible.
The Boston Globe story is one of the first products of their new health-and-medicine initiative, called “Stat“. That’s not short for “statistics;” it’s the medical slang meaning “right now”, from the Latin statum.