December 24, 2017
Christmas puzzle
The University is closed until after the New Year, so this is the StatsChat silly season.
To start with, a quiz question:
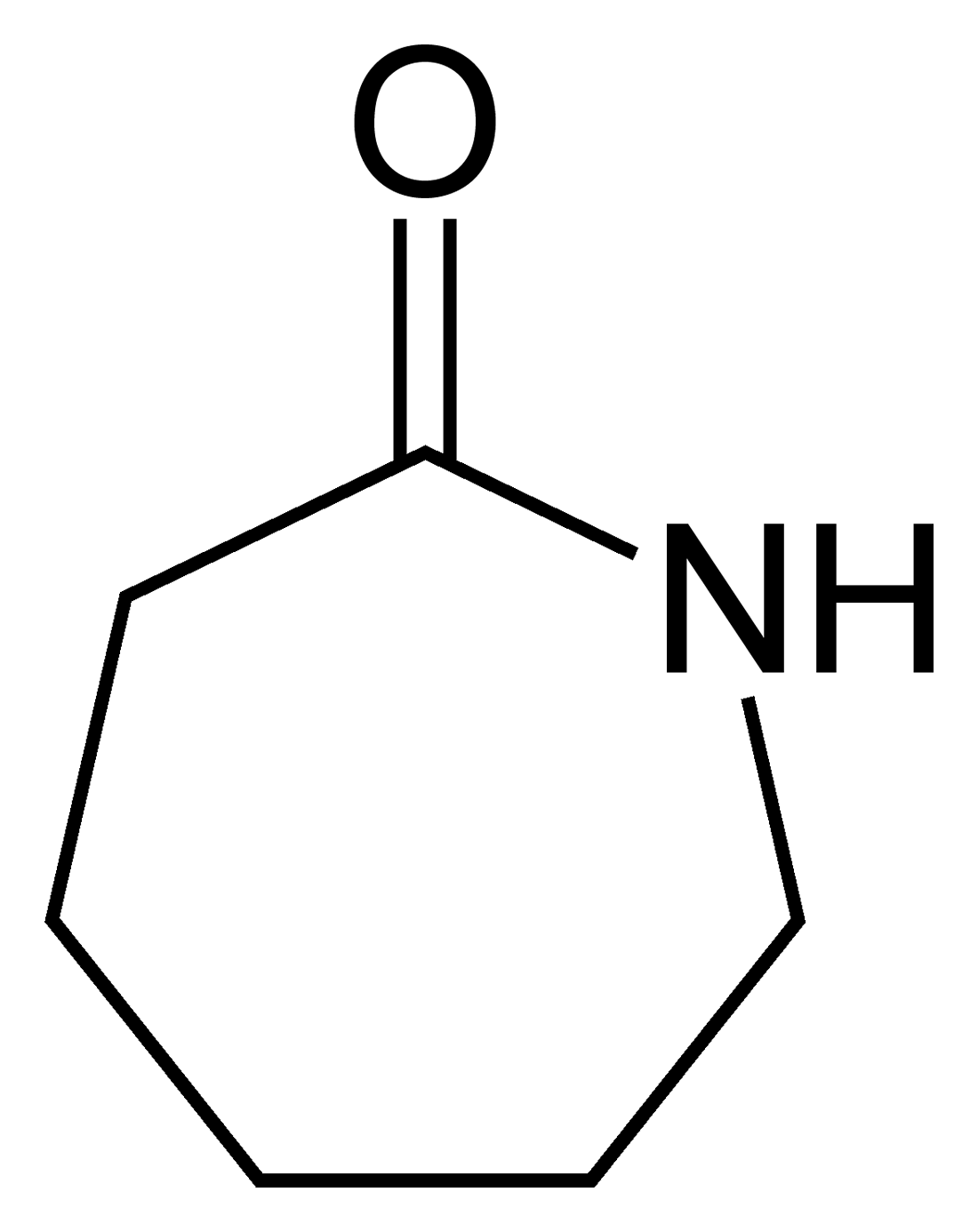
What is unusual and StatsChat-relevant about this molecule?
The University is closed until after the New Year, so this is the StatsChat silly season.
To start with, a quiz question:
What is unusual and StatsChat-relevant about this molecule?
From the New York Times, in what’s otherwise a really interesting story
The prospectors had unearthed what would come to be called the Patricia Emerald: a dazzling 12-sided crystal roughly the size of a soup can, with a weight of 632 carats — more than a quarter of a pound
If you have a rock `roughly the size of a soup can’ it’s going to weigh more than a soup can roughly the size of a soup can. A standard US can of soup has volume 10 fluid oz, and weighs over half a pound. The Patricia Emerald is more the size of one of those small coconut cream cans — which, to be fair, is seriously impressive for an emerald.
Q: Did you see there’s a diet that makes you burn energy ten times faster?
A: That … doesn’t sound very likely.
Q: It’s in the Herald
A: But it’s also in the Daily Mail.
Q: You could look up the research paper
A: <sigh>
A: Ok. Here it is.
Q: That took a while.
A: The story didn’t give the names of any of the researchers.
Q: Did the diet make people burn energy ten times faster?
A: No
Q: Mice?
A: It was people, but they didn’t burn energy ten times faster
Q: Are you sure?
A: Here’s the graph from the research paper: RMR stands for ‘resting metabolic rate’ and the colors indicate the groups
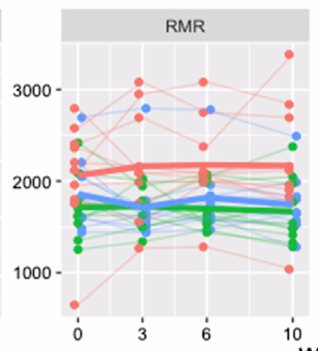
Q: The red line is higher. Is that the magic diet?
A: Yes.
Q: It’s not ten times higher
A: No
Q: Ten what, then?
A: The slope of the red line is ten times as steep as the slope of the other lines
Q: They all look kinda flat to me.
A: What’s ten times not a lot?
Q: Ok. Point. The red line looks higher right from the start. The story says “They were randomly placed into three groups”
A: … “in the order they signed up for the study.”
Q: Well, you can’t randomly assign them before they sign up. Oh. You mean they were just allocated to each group in turn.
A: Yes.
Q: Is that international best practice?
A: No.
Q: But does the diet work?
A: I don’t think the research adds much to what’s known about this question
Q: Which is?
A: Do you really think you’re going to get a simple and definitive solution to the low-carb diet controversy from a statistical blog?
Q: Ok, can I at least have some sort of sound bite?
A: Magic diet is not magic
Jenny Bryan @JennyBryan was one of several leading women in data science who attended this week’s joint conference of the New Zealand Statistical Association, the International Association of Statistical Computing (Asian Regional Section) and the Operations Research Society of New Zealand at the University of Auckland,  so we couldn’t miss the opportunity to talk with her (Jenny’s conference presentation, titled “Zen and the aRt of workflow maintenance”, is here). A brief bio: Jenny is a software engineer at RStudio while on leave from her role as Associate Professor in Statistics at the University of British Columbia, where she was a biostatistician. Jenny serves in leadership positions with rOpenSci and Forwards and is a member of The R Foundation. She takes special delight in eliminating the small agonies of data analysis.
so we couldn’t miss the opportunity to talk with her (Jenny’s conference presentation, titled “Zen and the aRt of workflow maintenance”, is here). A brief bio: Jenny is a software engineer at RStudio while on leave from her role as Associate Professor in Statistics at the University of British Columbia, where she was a biostatistician. Jenny serves in leadership positions with rOpenSci and Forwards and is a member of The R Foundation. She takes special delight in eliminating the small agonies of data analysis.
Statschat: When did you first encounter statistics as a young person? Jenny: I was an economics major which had exactly one required statistics paper, which I took, and then continued to try and make that degree as un-quantitative as I possibly could. I had started out thinking I would major in some form of engineering, and therefore was taking math and physics and the technical track.
I was one of very few women in the course, and the culture of the course was to pull an all-nighter once a week [to do the weekly problem set]. The average mark on the exam would be 20 out of 100, and I was mentally not prepared for this type of sort of stamina-driven culture.
Was it a macho culture? That’s how it felt to me, and you needed enough innate confidence to never worry about the fact that you were getting marks you had never seen before in your life – everyone failed miserably all the time. After the first semester or two of this, I decided it wasn’t for me and declared my major to be German literature, which I saw through. But in the last two years at university, I realised I needed to be employable when I graduated, so I added economics as a means to making sure I could make a living later.
I worked as a management consultant for a couple of years and that’s where I learned that I was actually at my happiest when they locked in a room by myself with a huge spreadsheet and I had some data task ahead of me … and so then I gradually worked my way back to what I think I’m really good at.
Did you pursue statistics qualifications? I did. After my two years of management consulting, the normal track would be to be sent off to business school. But thanks to what I learned about myself, I was pretty sure that wasn’t the right track for me. But I had learned how to give talks, how to extract questions from people and go and make it quantitative and then translate my solution back into their language. So the management consulting experience was super-useful.
At that point, I had met my husband, and I followed him to his first postdoc with no particular plans. He’s a mathematician – he knew he wanted to be a mathematician when he was 6. I never had that kind of certainty about what I was meant to do! It took me a lot longer to figure it out.
So I followed him, and basically played a lot of tennis at first (laughs) while were living in Southern California … I decided some form of statistics would be ideal for me, but I didn’t have enough of a math background to take the specialised math exams in the US, called the GREs [Graduate Record Examinations] that a lot of statistics departments want to see. So I started taking as many prerequisites as I could at the university where he was doing his postdoc. I did well and started working as a teaching assistant in these classes as well.
Then we moved together, two years later, for him to start his second postdoc and for me to start biostatistics grad school. Also during this time, I supported myself doing fancy Excel work as a temp … so I did a PhD in Biostatistics at Berkeley in five years – the first two years are the masters, and three years of writing the thesis.
What’s your academic career path been since then? I got my job at University of British Columbia before I graduated, and I was there until I went on leave earlier this year. I’ve since been working in Hadley Wickham’s group at RStudio. My title is software engineer, which I still find a bit peculiar.
Why? Because I feel I should have more formal training in engineering to have that title, but I’m getting more comfortable with it.
What’s the essence of your role there? I spend about two-thirds of my effort on package development and package maintenance. Hadley is starting to gradually give maintainership of his packages to other people … so I took over readxl. I already had an existing line of work in making R talk to Google APIs [application programming interface], so I worked with an intern this summer and we created a package from scratch so that you can use Google Drive from R. Now I’m revisiting some general tools for authenticating with Google APIs, and I have another package that talks to Google spreadsheets. I also do quite a bit of talking and teaching.
You put a lot of your work on the internet. Why do you feel that is important to share it this way? I decided this was how I was going to interpret what it meant to be a scholar. Several years ago, I decided that teaching people about the process of data analysis was super-important to me, and was being completely undertaught, and I was going to dedicate a lot of my time to it. Luckily, I already had tenure at that point, but it still looks a bit like career suicide to make this decision, because it means that you’re not producing conventional statistical outputs like methodological papers. I also felt like putting my stuff out there and having a public course webpage and pushing things out would be my defence against [any suggestion] that I wasn’t doing anything.
You’re clearly not satisfied that the current academic system is serving the subject well. Not at all! We have a really outdated notion that only publications matter, and publications where there’s novel methodology. I think that’s leaving a ton of value on the table – making sure that statistical methods that exist are actually used, or used correctly. But the field is not set up to reward that – the majority of papers are not widely read and cited, and many of these methods are not used or implemented in any practical way …. it’s been enshrined that academic papers are what counts, but they’re not a directly consumable good by society. We need knowledge-translation activity as well.
So you’re rebelling. Well, I felt that the only way you could do it was to start doing the things you thought were valuable. Being able to put your course material online, to have a dialogue with people in your field on Twitter … you can finally remove a lot of these gatekeepers from your life. They can keep doing their thing, but I know people care and read this stuff. Since I was able to wait until I had security of employment, I decided that if that meant I didn’t go from associate to full [professor], I could live with that. It’s not that my department isn’t [supportive] – it’s either neutral or positive on all this. But it’s true that everyone else I was hired with is a full professor and I’m not.
Does that bug you? Yes and no. I think I could have pushed harder. But every time you push on these things, you’re basically asked, “Well, can you make what you do look more like a statistics publication? Each package that you write, can you write a stats paper around it?” and I’ve decided the answer is, “No. Can we agree that is not a helpful way to evaluate this work? The only reason to repackage it in that way is to check some box.”
Academics are becoming increasingly dissatisfied with academic publishing structures. Do you think that perhaps data scientists might take the lead in dismantling structures that aren’t helping the subject? Maybe, and I think things are changing. But I decided that it’s like turning the Titanic and it’s not going to happen on a time-scale consistent with my career. I can’t wait for academia to gradually reshape itself.
Is that one of the reasons you went off to RStudio? Oh, absolutely. I feel the things I do are tolerated in academia, and often found very useful, [but that said], I lost my grant funding the more applied I became. It’s harder to get promoted. You’re pressured to sell your work as something it’s not, just because that’s what the status quo rewards. Working at RStudio, I’m actually allowed to say what I do is what I do, and be proud of it, and be told that you are excellent at it, which is not currently possible in academic statistics.
So tell me about your typical day, working for RStudio. It’s a remote company. There is an office in Boston and a large enough group in Seattle that they rent a space, but the rest of us are on our own. So it’s just me alone at home working on my projects. We use Slack as a communication channel; the team I’m on maintains two channels for two separate groups of packages. We might have a group conversation going and it can be completely silent for three days, or we can have 100 messages in a morning. It really depends when someone raises an issue that other people care about, or can help out with. And then, I have private one-off conversations with Hadley or other members of the group, and similarly, they can be very quiet or suddenly light up.
Who do you live with? My husband’s a professor, so he’s mostly on campus but sometimes he’s around – we both like working at home and being alone together. The kids are all at home; they go to school from 9am until 3pm or 4pm. My oldest is 14 and I have twins who are about to turn 12.
So how do you manage work-life balance, given that you work from home? Well, I work when they are not there, then I try to work from 3pm to 6pm, or 4pm to 6pm, with mixed success, I would say. Then there are a couple of hours which are explicitly about driving people here and there. I do a second shift from 9pm to 1am or 2am.
Are you a night owl? Yeah, which I don’t love, but that’s just how things are in my life right now. I have to do it that way. I have one productive shift while the children are at school, then one productive shift after they go to bed.
Let’s talk about women in data science. I have the impression that maths remains male-dominated and that statistics is less so, but that data science appeals to women and that the numbers are quite good. What’s your take on that? The reason I liked statistics, and particularly liked applied statistics, is I was never drawn to math for maths’ sake, or the inherent beauty of math. I enjoyed doing it in the service of some other thing that I care about … I think it’s possible that there’s something about me that’s typical of other women, where having that external motivation is what makes you interested in, or willing to do, the math and the programming. For its own sake, it never really appealed to me that much. Programming appeals to me more on its own than math does. Programming actually can motivate me just because I love the orderliness of it and accomplishing these little concrete tasks – I love checking lists (laughs) and being able to check my work and know that it is correct … When you combine it with, “This is going to enable us to answer some question”, then it’s really irresistible.
So it’s the real-world nature of it that is really appealing to you. Yeah – I care about that a lot.
What skills and attributes make a good data scientist? I think being naturally curious, doing something for the sake of answering the question versus a “will-this-be-in-the-test?” mentality – just trying to do the minimum.
You need a huge tolerance for ambiguity. This is a quality I notice that we’re spending a lot of time on in our Master of Data Science programme at UBC. Half the students have worked before and about half are straight out of undergrad, and the questions they ask us are so different. The people straight out of undergrad school expect everything to be precisely formulated, and the people who’ve worked get it, that you’re never going to understand every last thing; you’re never going to be given totally explicit instructions. Figuring out what you should be doing is part of your job. So the sooner you develop this tolerance for ambiguity [the better] – that makes you very successful, instead of waiting around to be given an incredibly precise set of instructions. Part of your job is to make that set of instructions.
How much room for creativity is there in data science? I think there’s a ton. There’s almost never one right answer – there’s a large set of reasonable answers that reasonable people would agree are useful ways of looking at it. I think there’s huge scope to be creative. I also think being organised and pleased by order frequently makes this job more satisfying. People come to you with messy questions and messy data, and part of what you’re doing is this sort of data therapy, helping them organise their thoughts: “What is your actual question? Can the data you have actually answer that question? What’s the closest we can get?” Do that, then package it nicely, you do feel like you’ve reduced entropy! It feels really good.
You work from home and that suits you, but not every woman is able to do that. What needs to change to help women scientists’ progress through life and career, balancing what they need to balance? I don’t how specific this is to data science, but three things were helpful to me. One is I live in Canada, where we have serious maternity leave – you can take up to a year, and because that’s what the Government makes possible, that means it’s normal. In both cases, I took between six and nine months – I was begging to come back before a year! But having a humane amount of time for maternity leave is important.
Also, what’s typical in Canada, and what and UBC does, is that they pause any sort of career clock for a reasonable amount of time. So every time I went on maternity leave it added one year to my tenure clock.
You don’t end up out of synch with people who hadn’t been away. Yeah. It [parenthood] still slows your career down, but this helps immensely. So there are the structural policies.
Secondly, I do have a really supportive spouse. I feel like maybe I was lead parent when the kids were little, but since I made this career pivot and became much more interested in my work, he’s really taken the lead. I feel that there were many years where I was the primary parent organising the household, and now it’s really the other way around … that’s huge.
Third, I’m in my mid-late 40s now and I’m embarking on what feels to me like a second career; certainly, a second distinct part of my career and focusing more on software development. I think you also have to be willing to accept that women’s careers might unfold on a different time-scale. You might lose a few years in your 30s to having little kids … but you often find awards that are for people within five years of their PhD or for young investigators and they assume that you don’t have all this other stuff going on. I think another thing is [employers] being willing to realise that someone can still be effective, or haven’t reached their peak, in their 40s. The time-frame on which all of this happens needs to be adjusted. You need to be flexible about that.
Read more about Jenny Bryan:
A profile by rOpenSci.org
In the US, the Federal Communications Commission was collecting public comments about ‘net neutrality’ — an issue that’s commercially and politically sensitive in a country where many people don’t have any real choice about their internet provider.
There were lots of comments: from experts, from concerned citizens, from people who’d watched a John Oliver show. And from bots faking real names and addresses on to automated comments. The Wall Street Journal contacted a random sample of nearly 3000 commenters and found the majority of those they could get in contact with had not submitted the comment attached to their details. The StartupPolicyLab attempted to contact 450,000 submitters, and got a response from just over 8000. Of the 7000 contacted about pro-neutrality comments, nearly all agreed they had made the comment, but of the 1000 responses about anti-neutrality comments, about 88% said they had not made the comment.
It’s obviously a bad idea to treat the comments as a vote. Even if the comments were from real US people, with one comment each, you’d need to do some sort of modelling of the vast majority who didn’t comment. But what are they good for?
One real benefit is for people to provide ideas you hadn’t thought of. The public comment process on proposed New Zealand legislation certainly allows for people like Graeme Edgeler to point out bugs in the drafting, and for people whose viewpoints were not considered to speak out. For this, it doesn’t matter what the numbers of comments are, for and against. In fact, it helps if people who don’t have something to say don’t say it.
With both petitions and public comments there’s also some quantitative value in showing that concern about some issue you weren’t worrying about isn’t negligibly small; that thousands (in NZ) or hundreds of thousands (in the US) care about it.
But if it’s already established that an issue is important and controversial, and you care about the actual balance of public opinion, you should be doing a proper opinion poll.
Alabama senate exit polls: bars scaled by % in each group#statschat (now with white background)
(data from https://t.co/Jz2IqSwBKP …) pic.twitter.com/cqJTE0156S— Thomas Lumley (@tslumley) December 13, 2017
Australian Di Cook @visnut was one of several leading women in data science who attended this week’s joint conference of the New Zealand Statistical Association, the International Association o f Statistical Computing (Asian Regional Section) and the Operations Research Society of New Zealand at the University of Auckland, so we couldn’t miss the opportunity to talk with her. A brief bio: Di is a world leader in data visualisation and well-known for her work on interactive graphics. She is Professor of Business Analytics in the Department of Econometrics and Business Statistics at Monash University. She’s a Fellow of the American Statistical Association, elected member of the R Foundation and the Editor of the Journal of Computational and Graphical Statistics. Her research lies in data science, data visualisation, exploratory data analysis, data mining, high-dimensional methods and statistical computing.
f Statistical Computing (Asian Regional Section) and the Operations Research Society of New Zealand at the University of Auckland, so we couldn’t miss the opportunity to talk with her. A brief bio: Di is a world leader in data visualisation and well-known for her work on interactive graphics. She is Professor of Business Analytics in the Department of Econometrics and Business Statistics at Monash University. She’s a Fellow of the American Statistical Association, elected member of the R Foundation and the Editor of the Journal of Computational and Graphical Statistics. Her research lies in data science, data visualisation, exploratory data analysis, data mining, high-dimensional methods and statistical computing.
Statschat: When did you first encounter statistics? Di: It was in my undergraduate degree. I studied mathematics with a plan to do math teaching. Statistics was one of the areas of mathematics that I could major in other than pure, or applied, mathematics. There was an extremely good female professor at the University of New England, Eve Bofinger, and I was drawn to some of the methods she was teaching, and that led me into statistics.
What was your career path after that? I taught math at high school for about three months, then I had an offer from the Australian National University to go there as a research assistant, and that seemed a better fit. As a research assistant, I got to learn a lot more things, particularly computing. Computing, I think, is a critical aspect of data science today.
I spent a few years doing that and then realised I’d really like to make art, because some of the research-assistant work I was doing was computer graphics for data online. It fed into my art instincts from teenage years, so I spent some time as an artist before finding a graduate programme in statistics in the US that focused on data visualisation.
What sort of art do you do? I was painting – I haven’t done any for a long, long time, since I finished my PhD; it’s been too busy.
So your creative pursuits have fed into your career. Yeah – seeing that I could do data visualisation as a part of the statistics allowed me to realise that I could do a higher degree in stats; that merged my interests very well.
Where did you do your PhD? At Rutgers University in New Jersey.
You spent 22 years at Iowa State University in the US, and moved to Monash in Australia in 2015. What are your major projects there? I have a lot of projects. One of them is with Tennis Australia; we’ve been looking at tennis serves. So we have Hawk-Eye trajectory data and we visualise the tennis serves and look at how the players are different or similar.
That’s very cool – how’s that for applied statistics. Yeah, it’s fantastic, isn’t it. We’re also looking at face recognition in tennis video, to be able to detect the face through broadcast video, so that we can monitor emotions throughout a match and see how that affects performance.
We’re also looking at pedestrian sensor data, that comes from a city of Melbourne (almost live) feed. One of my PhD students, Earo, has a new type of plot called a calendar plot; you make your data plots into a calendar format so that you can study things relative to holidays, and put it really on a human pattern basis.
Describe a typical day at work at Monash. We have a lot of meetings with students, so I would meet up with two or three students – PhD students or postdocs or research assistants – on projects that we’re working with, and meet up with other faculty. On some days I’m teaching data science classes to around 200 students. We often just go for a coffee with colleagues. We also play ping-pong on the conference table! I’ve got a good group of colleagues who play tennis, so we play tennis together.
It sounds very collegial. You’re a prominent woman in data science, and the field seems to appeal to women as a career path. Do have any thoughts on that? I haven’t really looked at those numbers … but honestly, I think there’s too big of an emphasis on gender differences, and they’re not real when you look at the metrics. It’s just a perception. But one of the things I notice with the women that I work with is that they are interested in solving problems, and having an outcome of their work that makes life better for others. And that’s one thing that data science offers that pure statistics research is a bit removed from.
Do you have a family? I have one son. I moved to Monash after he graduated high school. He went off to college in the US, while I moved halfway across the globe, which he was quite happy about. He visits during the holidays, and last American summer found an internship at Monash University.
When he was small, how did you navigate work and life? It’s really difficult. I can’t imagine how single women do that – you need to have some sort of support mechanism. Day-care is amazing – and however much you spend on day-care, it’s worth it. And also partly because I think young kids early on really get a huge amount of benefit from being in the social mix of other kids the same age. He was in day-care from three months, part-time, and even at five months, if we were away for a week, when he’d get back, the other babies were over the moon – they recognised each other. I hadn’t realised how early on that socialisation happens.
So you weren’t concerned about day-care at all. Some women get tied up in knots about putting their kids in day-care. I know – there’s this thing about guilt. It is actually the best environment – they [pre-school educators] can do a much better job than me. If my time pressure is relieved by not having to have every moment dealing with all the stuff you have to deal with young kids … he’s come out as being a very sociable child and that he learnt from early on. Guaranteed when you’ve got the most important meeting, and your husband has a most important meeting at exactly the same time, that’ll be the time your kid gets sick. So you have to have a backup.
So what advice do you give other academic mums? Don’t stress – there are ways around. And the meeting you think is most important doesn’t have to be the most important. You just juggle everything you have as well as you can, and there are ways around any hurdle or hiccup. Just keep out there. It’s really important for other younger women to see women in senior roles.
Are universities doing the necessary to help women make the most of their talents in data science? I think it’s still a struggle. I think there’s been bureaucratic pushes for gender equality, which is really how I actually got an academic position in the first place in the US.
How so? Equal opportunity. Many statistics departments had no women, and it was a cultural shift in the early 1990s that many university administrations were forcing departments to hire women … or otherwise they couldn’t hire … if they [universities] were doing it well, they were not putting women in that situation of thinking, “Oh I was only hired because I was a woman”. They were doing it in the sense of making sure that women realised that they were talented, and wanted for their talents, not just because of the administration push. But that wasn’t universal.
I thought things have been solved, but it’s not. Time and time again women are evaluated differently at promotion, and in classroom evaluations, they are not on average [rated to be] as good as the men, and that’s been shown again and again and again. So the thing is, don’t get put off by that; you will sometimes need to fight for your promotions and have people willing to fight for you.
Systemically, things are still not weighted fairly between men and women. It’s not. I’ve just finished studying some of the research-grant rates in Australia and the number given to women faculty are pitiful, from both the Australian Research Council and the National Health and Medical Research Council, which is the health sciences. That impacts whether women can get through to those higher ranks. That’s my next fight.
Would you see yourself as a crusader? How do you define yourself in exposing these inequalities? We’ve seen a lot of things [around sex, privilege and power discussed] in public in these last few months, with the sex scandals in Hollywood. I’ve seen that all through my career in academia. I think we, hopefully, are on a cusp where the playing field for recognising talent among women becomes more level … I had advantages early on, and I feel like I need to pay that back.
I wouldn’t say I’m a crusader; I’m saying I see where we’ve come from, in terms of generations of women in my family, and where we are now, and we’ve come a long, long way. I’ve had so many more opportunities than my mum and my grandmother … I feel like I’ve got a responsibility to those generations to keep it moving in the right direction.
What advice would you give young women looking at a career in data science? What skills and attributes do they need to develop? Get onto the publicly available software – free software like R and Python – and get to know them. These are hugely powerful, and they give you power. There’s a number of courses you can do for free to help learn how to work with data.
Any particular courses that you would recommend? There’s Data Camp and Corsera and Software Carpentry, among others. Work with data. Play. Extract somebody’s tweets and analyse the text – there are really good resources for that. Pull data from the government web pages – they have lots of information. The New Zealand Herald has lots of data available. Just get comfortable finding data, making plots of it, and seeing whether it matches up what the media is reporting about a problem. This is the sort of power you can get over your life if you can make decisions yourself, rather than being fed decisions.
Read more about Di Cook:
Some time in the next week or so, we should be getting the ACC Christmas Sermon, where we get told about how many accidents happen on Christmas Day. From last year’s version in the Herald
Every year, more than 3400 claims are lodged with ACC for Christmas Day incidents, costing the country almost $3million.
As I always point out, that’s a lot less than the number lodged on a typical day that isn’t Christmas. On the other hand, many of those 3400 are genuinely Christmas-caused injuries; accidents that would not have happened on some random day in summer.
You can look at Christmas-attributable risk by considering individual cases and counting the number that involve new toys, Christmas trees, batteries inserted in appropriately, misuse of wrapping paper, etc, etc. Or, you can compare Christmas to an otherwise similar day.
Rafa at Simply Statistics writes about a more serious example.
The official death toll from Hurricane María in Puerto Rico is 55. That’s 55 people whose death can be specifically and clearly attributed to the hurricane. However, the number of recorded deaths from all causes in September was 2838, which is 455 above the average for September in recent years. The next largest exceedance in the past seven years was just over 200 in November 2014.
Attributing deaths on a case-by-case basis to a disaster like María is hard; it would be hard to make those sorts of decisions even without the continuing post-hurricane disruption. Another example is deaths due to the 2003 power outage in New York, where there were 6 officially-attributed deaths but a spike of 90 in the total death statistics.
Sometimes we want to look at specifically attributable cases: when snow shuts down the roads, we probably want to count the number of snow-caused crashes without subtracting the number of snow-prevented ones. But for natural disasters it’s probably the total excess deaths we want.
If you click through, things are less local and immediate: ATMs could be extinct in Australia within 30 years
Apparently
A projection of data from the Reserve Bank of Australia by finder.com.au has found ATMs could be a distant memory in Australia by 2036.
2036 is in 19 years, and 19 is less than thirty, so I suppose that counts as within 30 years. So how did they do the projection? There’s not much detail in the story and I couldn’t find any on finder.com.au.
The story says
According to finder.com.au, the number of ATM withdrawals per month has fallen from a high of 73 million in 2010 to just 47 million this year. If the trend continues at the same rate, ATM use will reach zero in three decades.
Now, I can fit a straight line to data. They teach you this in statistics. They often also teach you not to do it with just two points, but whatever
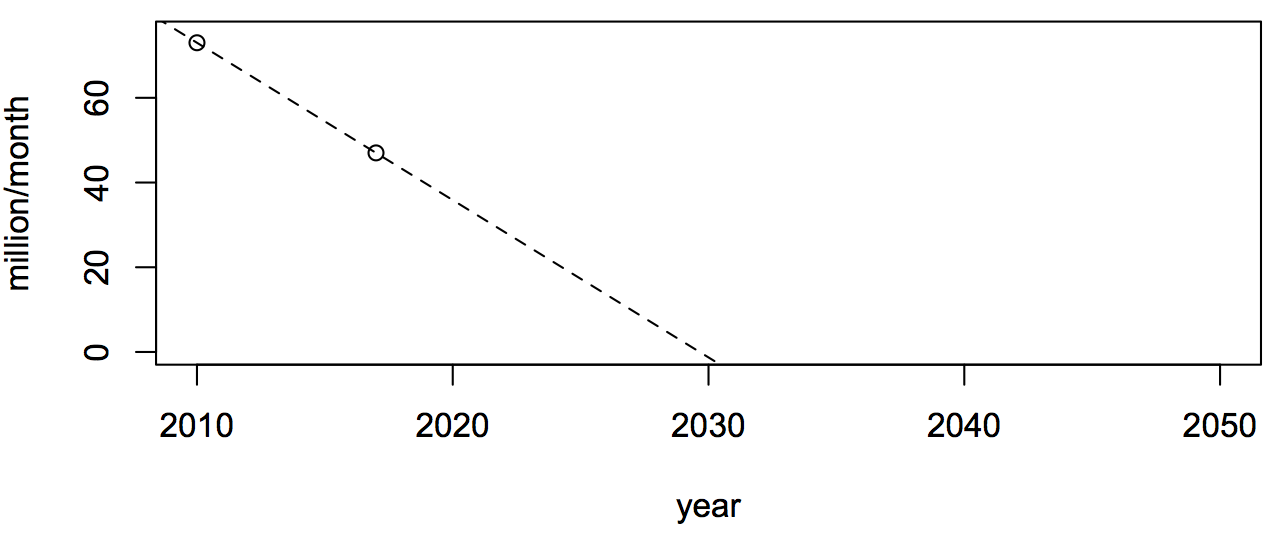
Ok, maybe finder.com.au had more data or more detailed data or something, but the information in the story is all we have, and it doesn’t really support either “2036” or “30 years”
I don’t know how long ATMs will last. And I don’t think finder.com.au does either. But they do know how to get a free mention in the Herald.
From Stuff
Your summer pavlova costs more than 40 per cent more to make this year than it did 10 years ago – and commentators think that trend will continue.
That’s true, but prices now and prices ten years ago are in different currencies, and so shouldn’t just be compared like numbers.
Using the RBNZ inflation calculator, about half the apparent price increase is just currency conversion; a 2007 dollar is worth about 1.2 2017 dollars.
On top of that, incomes have changed over the past ten year. The median annual household income is up about 36%, so if pavlova is less affordable than in 2007 it’s mostly because of something like housing costs, not the price of cream and kiwifruit.
Recent comments