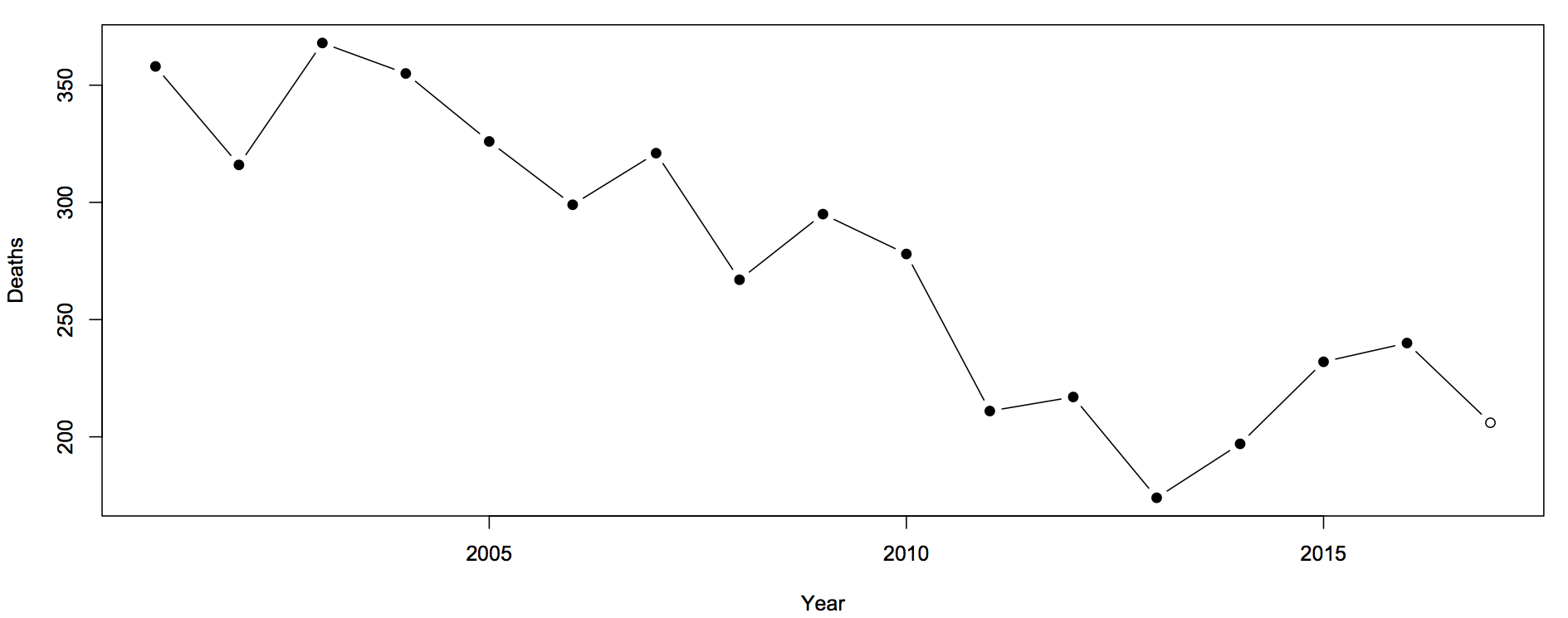
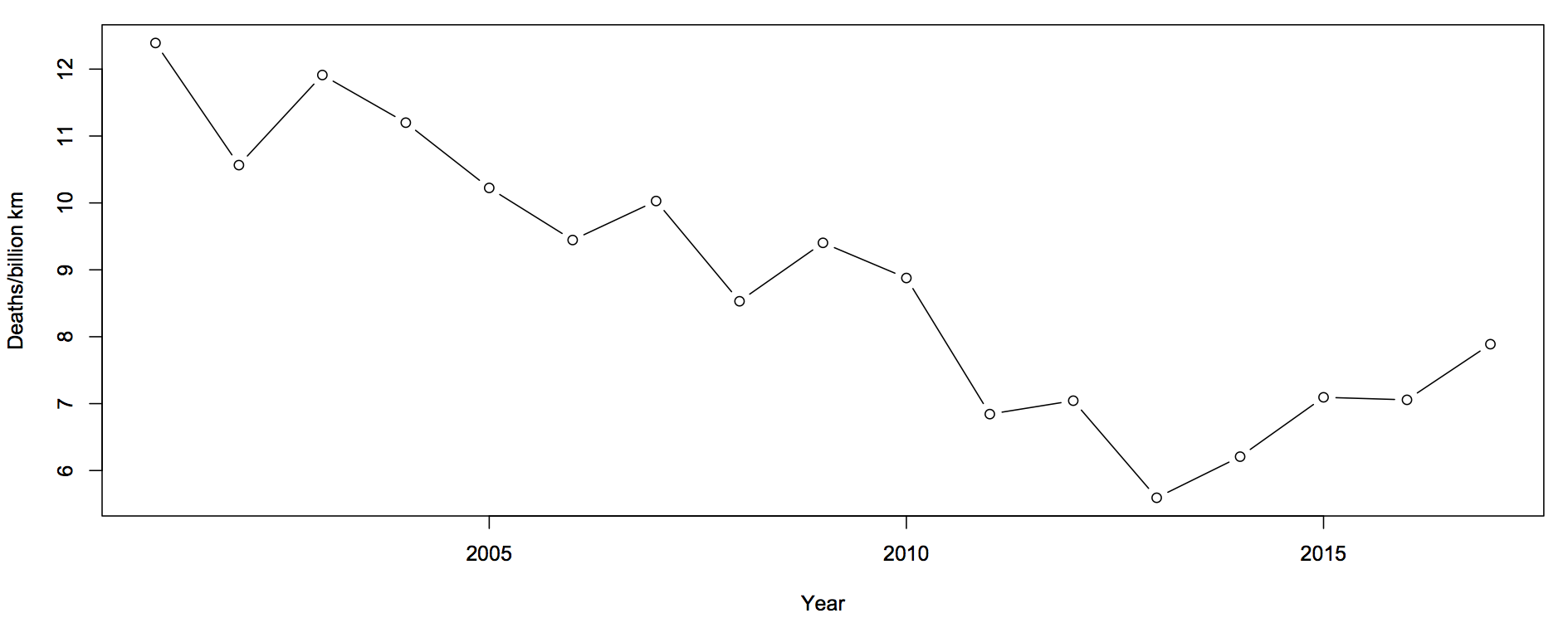
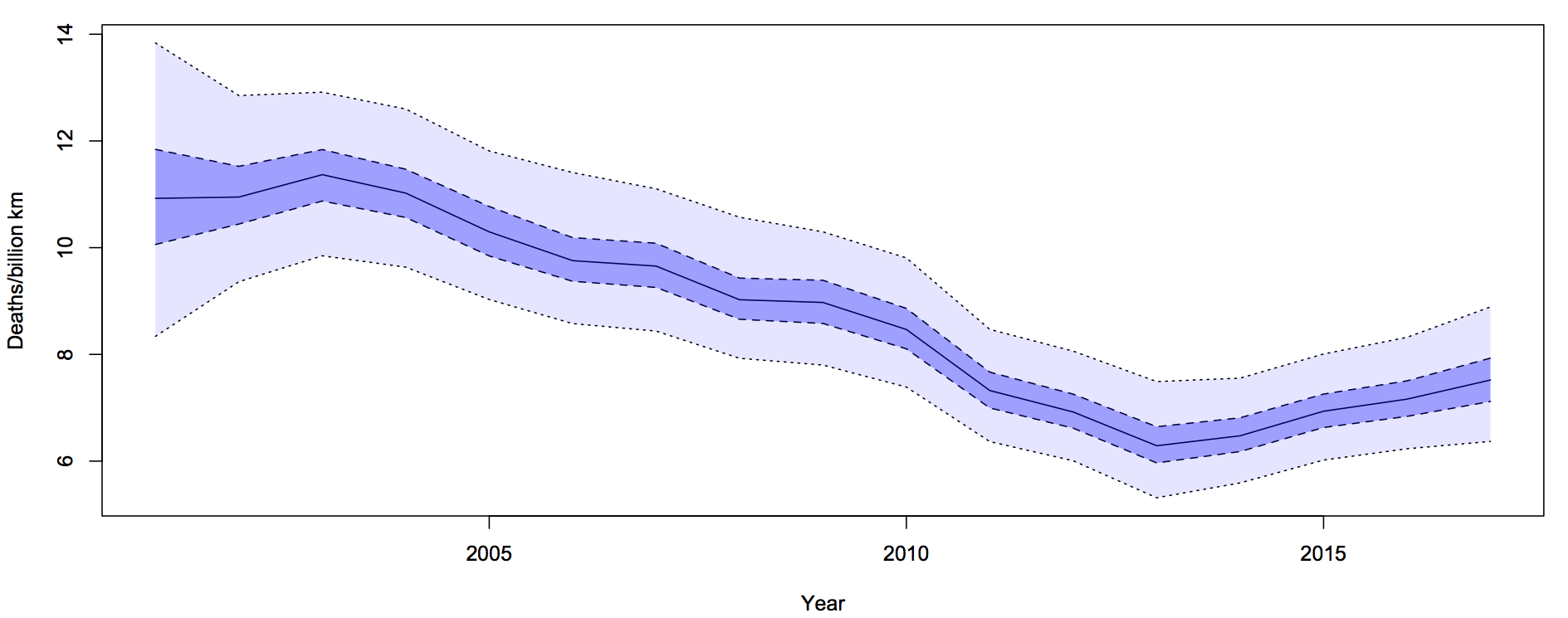
Diagnostic accuracy: twitter followers
The New York Times and Stuff both have recent stories about fake Twitter followers. There’s an important difference. The Times focuses on a particular company that they claim sells fake followers; Stuff talks about two apps that claim to be able to detect fakes by looking at their Twitter accounts.
The difference matters. If you bought fake followers from a company such as the one the Times describes, then you (or a ‘rogue employee’) knew about it with pretty much 100% accuracy. If you’re relying on algorithmic identification, you’d need some idea of the accuracy for it to be any use — and an algorithm that performs fairly well on average for celebrity accounts could still be wrong quite often for ordinary accounts. If you know that 80% of accounts with a given set of properties are fake, and someone has 100,000 followers with those properties, it might well be reasonable to conclude they have 80,000 fake followers. It’s a lot less safe to conclude that a particular follower, Eve Rybody, say, is a fake.
Stuff says
Twitter Audit analyses the number of tweets, date of the last tweet, and ratio of followers to friends to determine whether a user is real or “fake”.
SocialBakers’ Maie Crumpton says it’s possible for celebrities to have 50 per cent “fake” or empty follower accounts through no fault of their own. SocialBakers’ labels an account fake or empty if it follows fewer than 50 accounts and has no followers.
Twitter Audit thinks I’ve got 50 fake followers. It won’t tell me who they are unless I pay, but I think it’s probably wrong. I have quite a few followers who are inactive or who are read-only tweeters, and some that aren’t real people but are real organisations.
Twitter users can’t guard against followers being bought for them by someone else but Brislen and Rundle agree it is up to tweeters to protect their reputation by actively managing their account and blocking fakes.
I don’t think I’d agree even if you could reliably detect individual fake accounts; I certainly don’t agree if you can’t.