Our most-viewed posts in the past year, according to the Jetpack backend
- Tip of the icecube: on the ‘hundreds of unfit teachers’
- Who is really buying New Zealand: dramatically bad bubble graphs
- A story from last year, about the suicide rate at the Foxconn plant
- David Scott’s Super 15 predictions for round 2
- Another one from last year, on lottery odds.
This only counts hits directly on the page (eg from Twitter or RSS feeds), not from browsing the site, so it misses about 1/3 of the traffic.
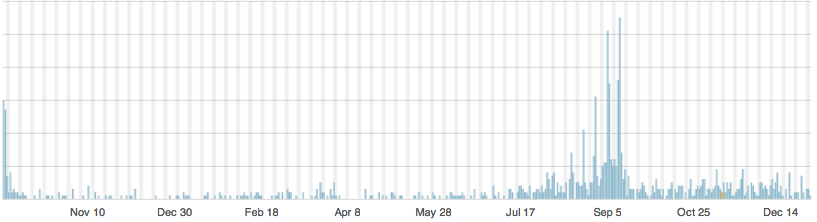
The lottery post shows an interesting pattern of hits
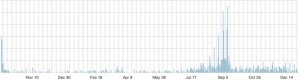
The second burst of popularity was a building jackpot, with the spikes on Tuesday/Wednesday each week. There’s a similar pattern on Google Trends for the phrase ‘Big Wednesday’.
There were 31 posts in the new ‘Denominator’ category, which mostly follows violations of two of the most basic numeracy principles for reporting:
- Auckland is bigger than the other cities, so simply having more of something in Auckland is not news
- If you have two years of data, either take an average or a difference. Don’t report a total.
Approximately 95% of our comments were spam, but the filters caught 99.8% of it. The 5% of real comments are much appreciated.
And finally, the title of this post is from an Ogden Nash poem.


{kind=link}