What does 80% accurate mean?
From Stuff (from the Telegraph)
And the scientists claim they do not even need to carry out a physical examination to predict the risk accurately. Instead, people are questioned about their walking speed, financial situation, previous illnesses, marital status and whether they have had previous illnesses.
Participants can calculate their five-year mortality risk as well as their “Ubble age” – the age at which the average mortality risk in the population is most similar to the estimated risk. Ubble stands for “UK Longevity Explorer” and researchers say the test is 80 per cent accurate.
There are two obvious questions based on this quote: what does it mean for the test to be 80 per cent accurate, and how does “Ubble” stand for “UK Longevity Explorer”? The second question is easier: the data underlying the predictions are from the UK Biobank, so presumably “Ubble” comes from “UK Biobank Longevity Explorer.”
An obvious first guess at the accuracy question would be that the test is 80% right in predicting whether or not you will survive 5 years. That doesn’t fly. First, the test gives a percentage, not a yes/no answer. Second, you can do a lot better than 80% in predicting whether someone will survive 5 years or not just by guessing “yes” for everyone.
The 80% figure doesn’t refer to accuracy in predicting death, it refers to discrimination: the ability to get higher predicted risks for people at higher actual risk. Specifically, it claims that if you pick pairs of UK residents aged 40-70, one of whom dies in the next five years and the other doesn’t, the one who dies will have a higher predicted risk in 80% of pairs.
So, how does it manage this level of accuracy, and why do simple questions like self-rated health, self-reported walking speed, and car ownership show up instead of weight or cholesterol or blood pressure? Part of the answer is that Ubble is looking only at five-year risk, and only in people under 70. If you’re under 70 and going to die within five years, you’re probably sick already. Asking you about your health or your walking speed turns out to be a good way of finding if you’re sick.
This table from the research paper behind the Ubble shows how well different sorts of information predict.
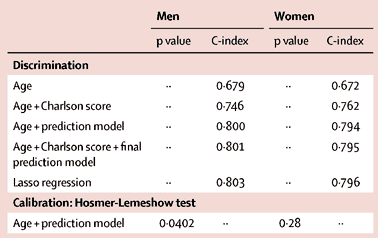
Age on its own gets you 67% accuracy, and age plus asking about diagnosed serious health conditions (the Charlson score) gets you to 75%. The prediction model does a bit better, presumably it’s better at picking up a chance of undiagnosed disease. The usual things doctors nag you about, apart from smoking, aren’t in there because they usually take longer than five years to kill you.
As an illustration of the importance of age and basic health in the prediction, if you put in data for a 60-year old man living with a partner/wife/husband, who smokes but is healthy apart from high blood pressure, the predicted percentage for dying is 4.1%.
The result comes with this well-designed graphic using counts out of 100 rather than fractions, and illustrating the randomness inherent in the prediction by scattering the four little red people across the panel.

Back to newspaper issues: the Herald also ran a Telegraph story (a rather worse one), but followed it up with a good repost from The Conversation by two of the researchers. None of these stories mentioned that the predictions will be less accurate for New Zealand users. That’s partly because the predictive model is calibrated to life expectancy, general health positivity/negativity, walking speeds, car ownership, and diagnostic patterns in Brits. It’s also because there are three questions on UK government disability support, which in our case we have not got.

Recent comments