Measuring what you care about
Via Felix Salmon, here’s a chart from Credit Suisse that’s been making the headlines recently, in the Oxfam report on global wealth. The chart shows where in the world people live for each of the ‘wealth’ deciles, and I’ve circled the most interesting piece.
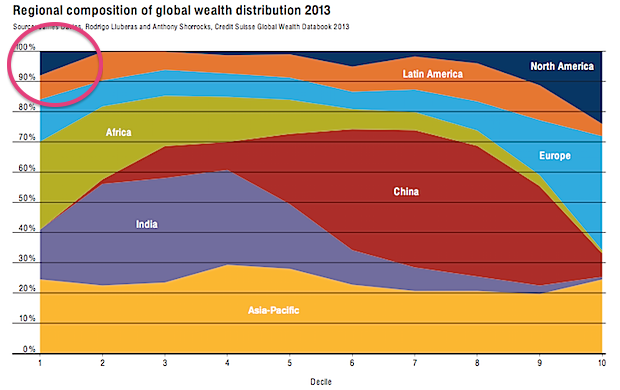
About 10% of the least wealthy people in the world live in North America. This isn’t (just) Mexico, Guatemala, Nicaragua, etc, it’s also the US, because some people in the US have really big debts.
If you are genuinely poor, you can’t have hundreds of thousands of dollars of negative wealth because no-one would give you that sort of money. Compared to a US law-school graduate with student loans, you’re wealthy. This is obviously a dumb way to define wealth. Also, as I’ve argued on the ‘net tax’ issue, cumulative percentages just don’t work usefully as summaries when some of the numbers are negative.
This doesn’t mean wealth inequality doesn’t exist (boy, does it) or doesn’t matter, but it does mean summaries like the Credit Suisse one don’t capture it. If you wanted to capture the sort of wealth inequality worth worrying about, you’d need to think about what it really meant and why it was a problem separately from income inequality (which is much easier to define).
There seem to be two concerns with wealth inequality that people on a reasonably broad political spectrum might care about, if we stipulate that redistributive international taxation is not on the agenda:
- transfer of wealth from parents to children leads to social stratification
- high concentrations of wealth give some people too much power (and more so in societies more corrupt than NZ).
Both of these are non-linear ($200 isn’t twice as much as $100 in any meaningful sense) and they both depend on where you are ($20,000 will get you much further in Nigeria than in Rhode Island). There probably isn’t going to be a good way to look at global wealth inequality. Within countries, it’s probably feasible but it will still take some care and I expect it will be necessary to discount debts quite a lot. If you owe the bank $10, you’re not wealthy, but if you owe the bank $10 million, you probably are.




Recent comments