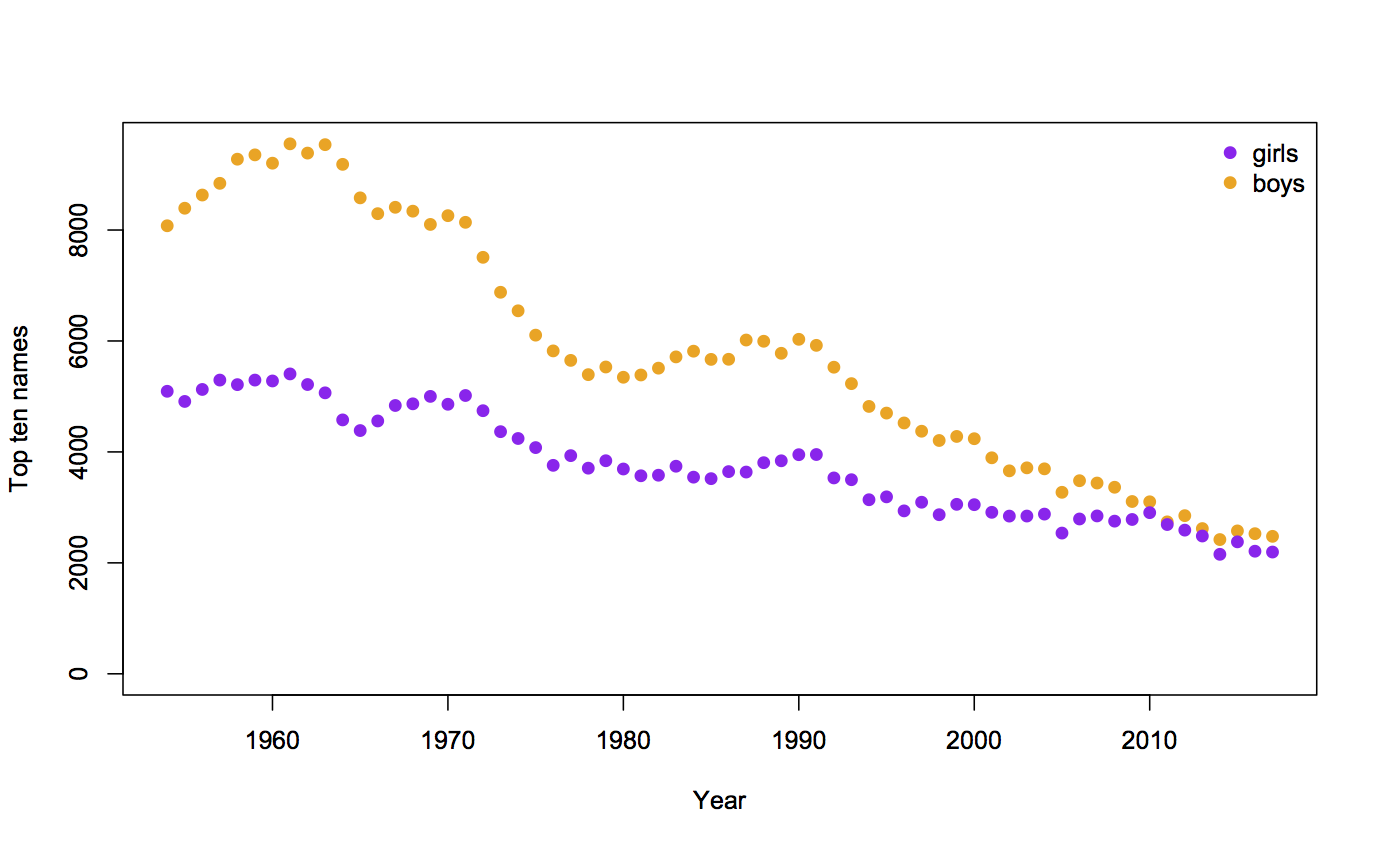
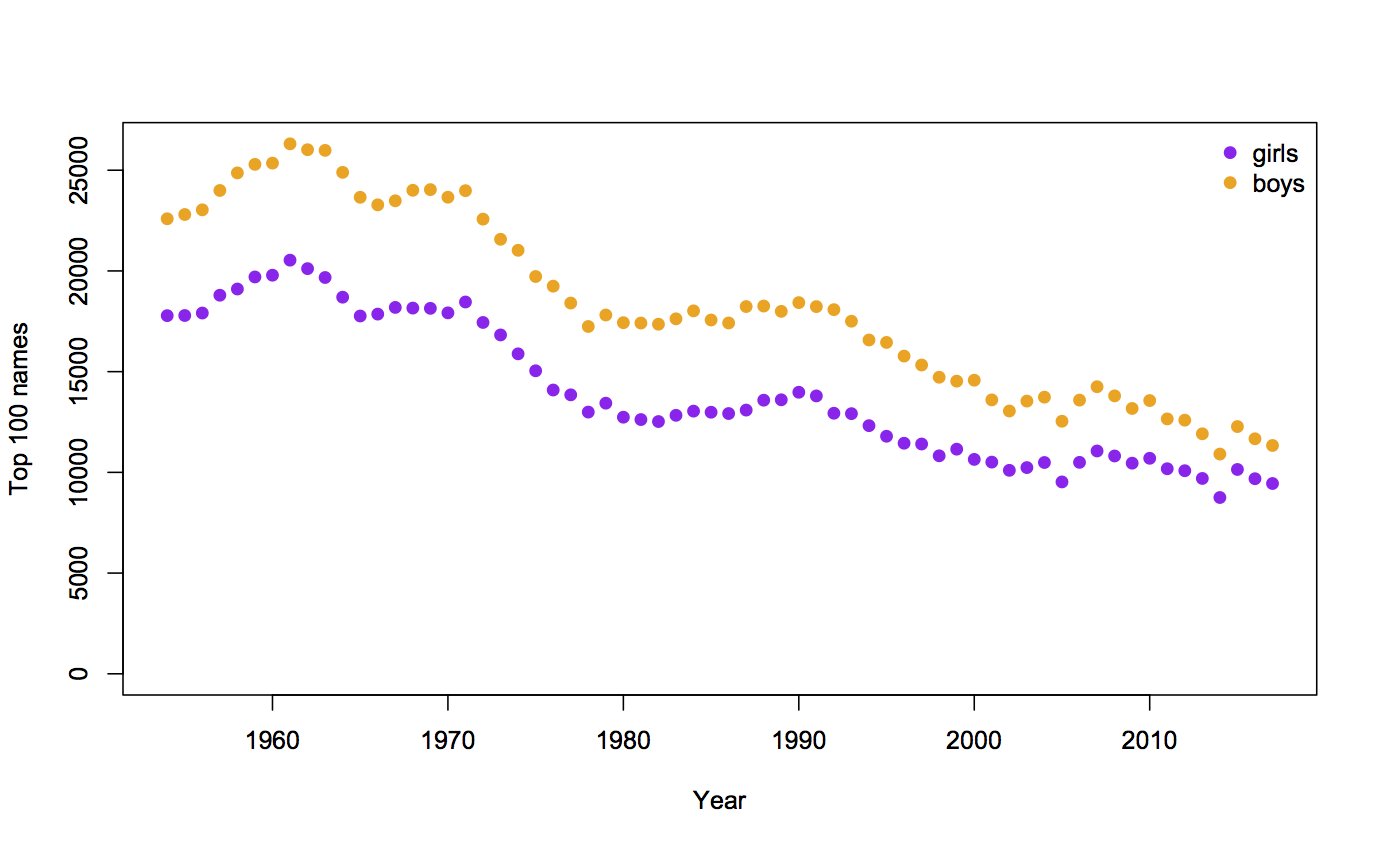
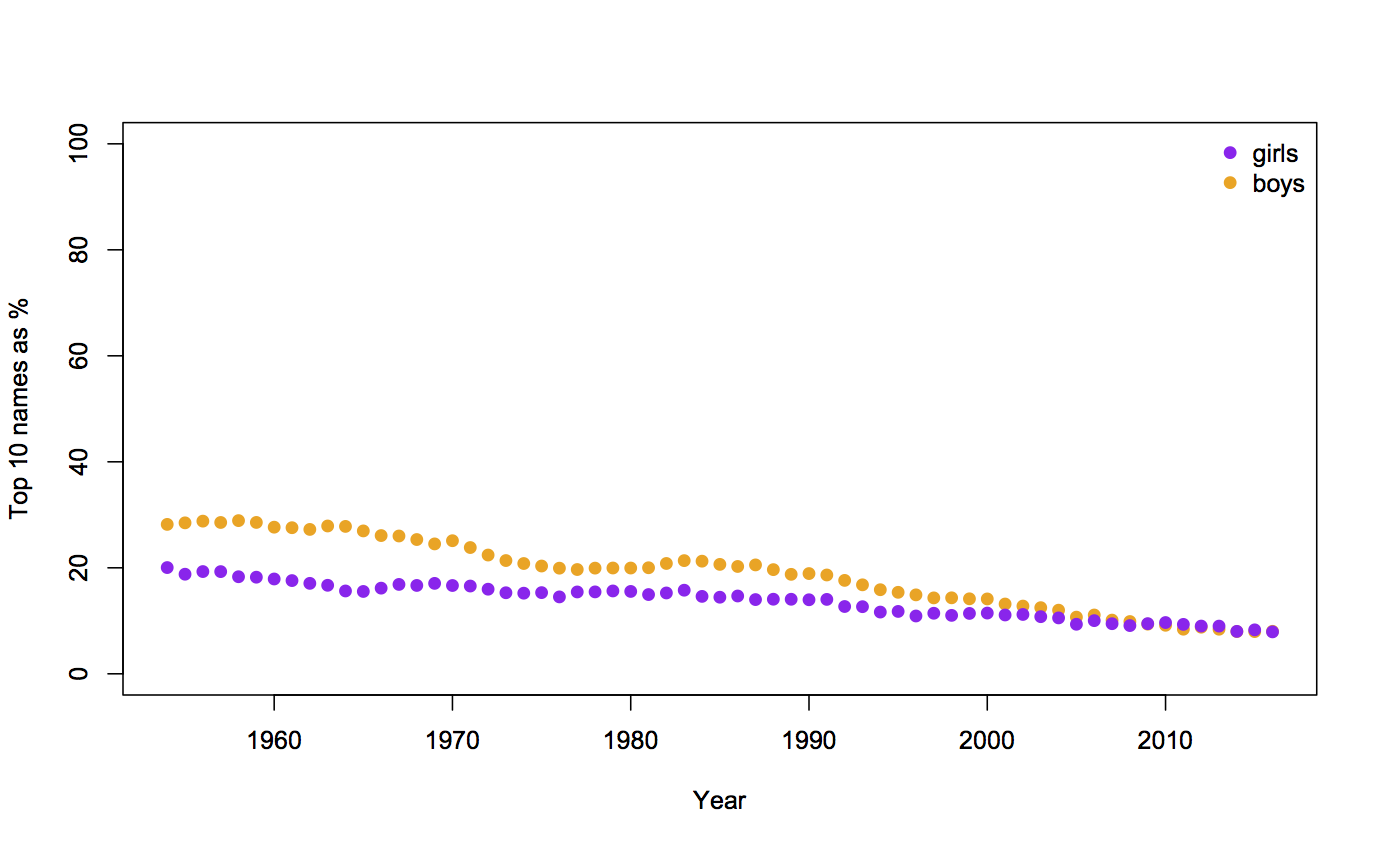
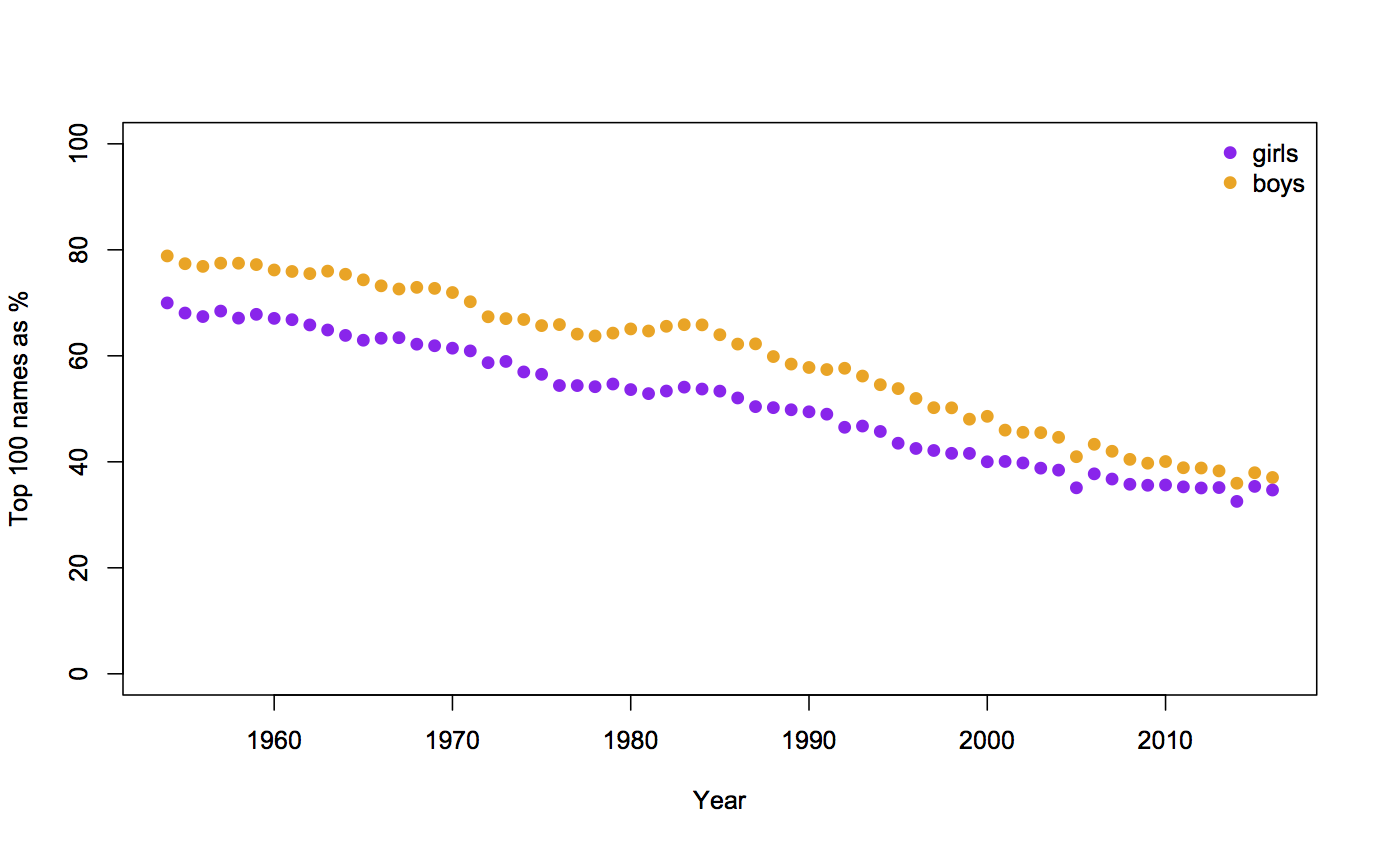
Auckland is larger than Wellington
The Herald is reporting on the Government’s new road-cone hotline. Apparently there were 236 reports in the first four days, and the article usefully points out that this was about 100 for each of the first two days, so it dropped pretty fast after that.
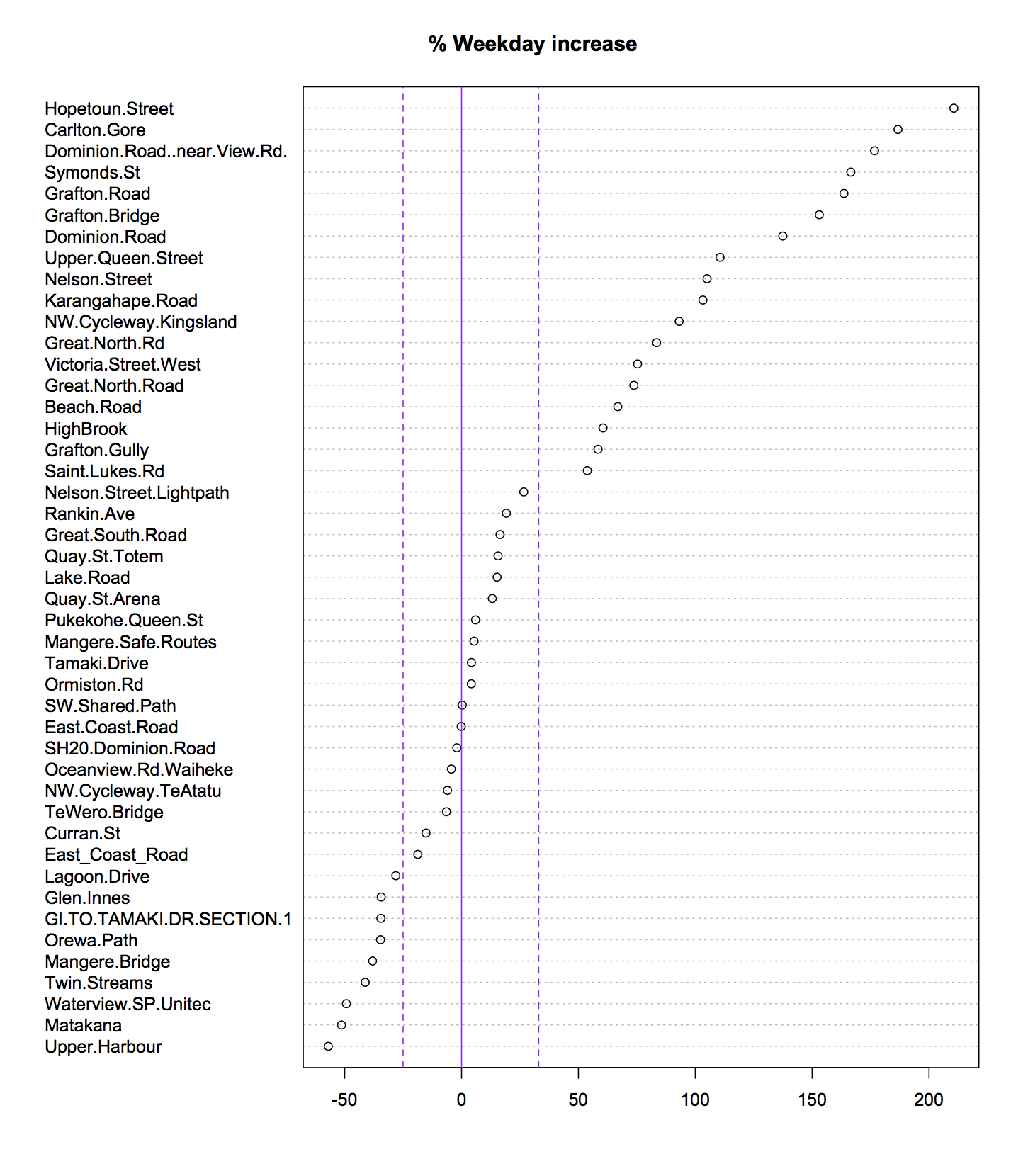
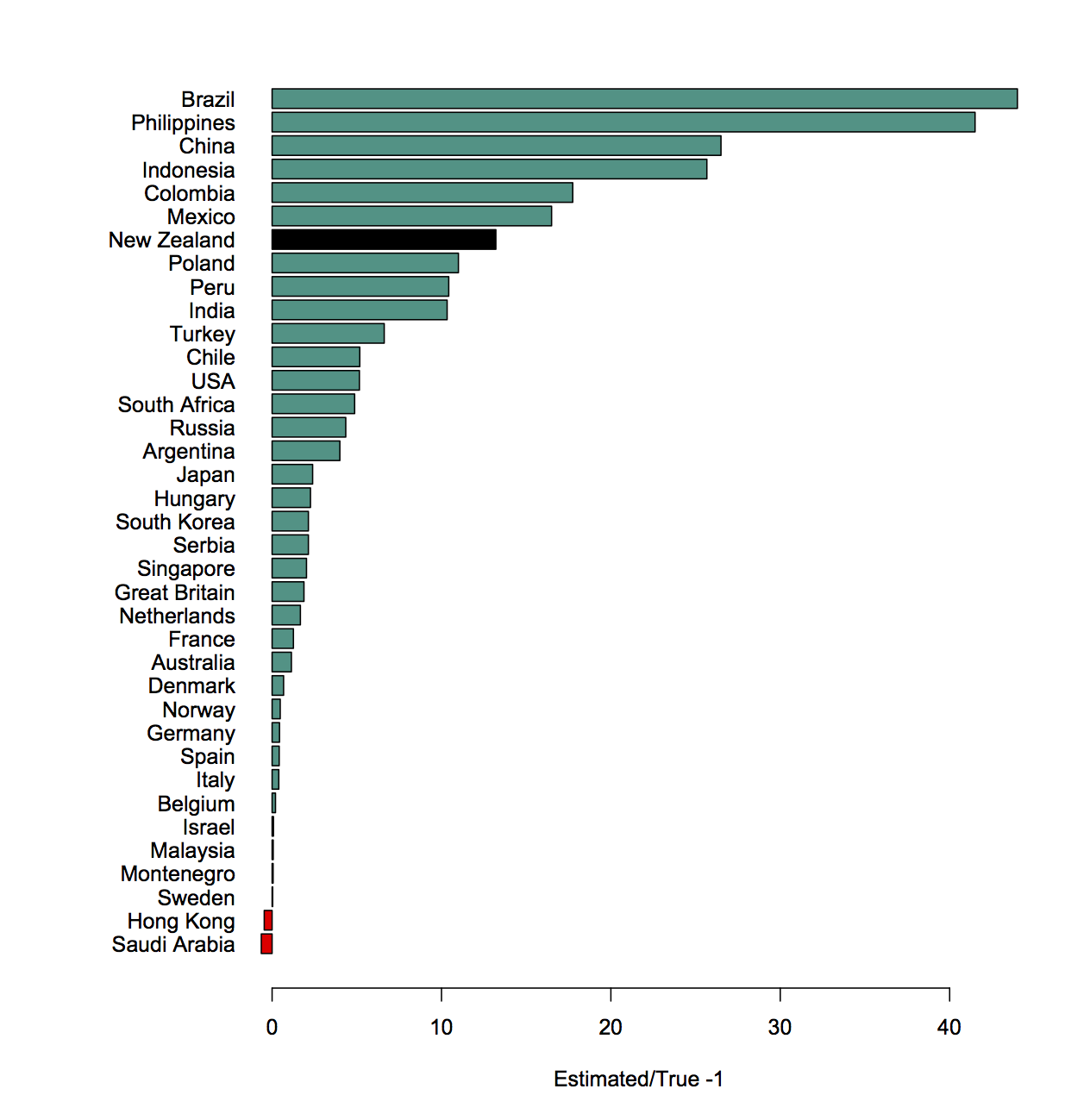
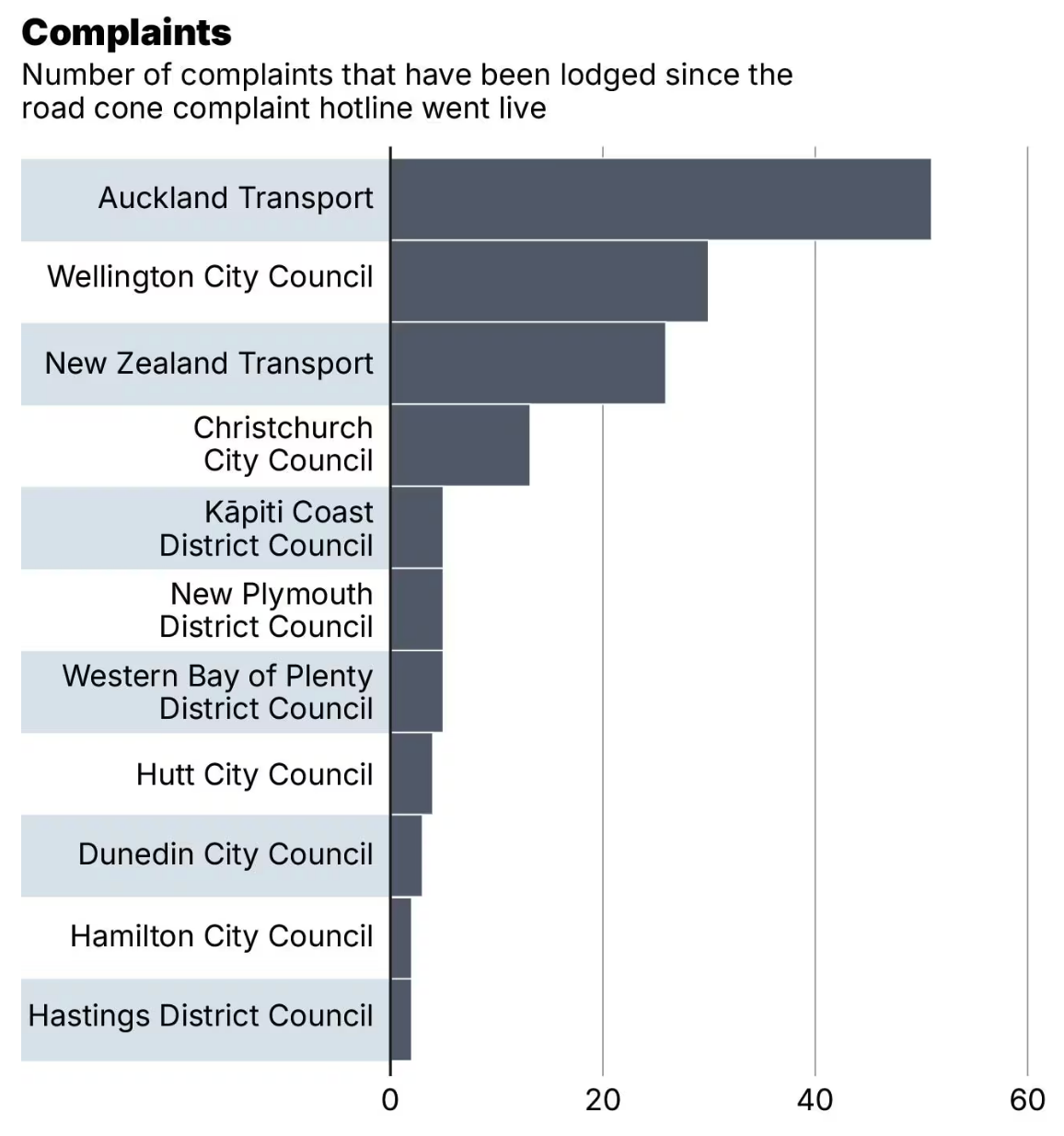
A bit less usefully, there’s a graph (click to embiggen) of reports by miscellaneous administrative category . Auckland (region), as usual, is at the top.
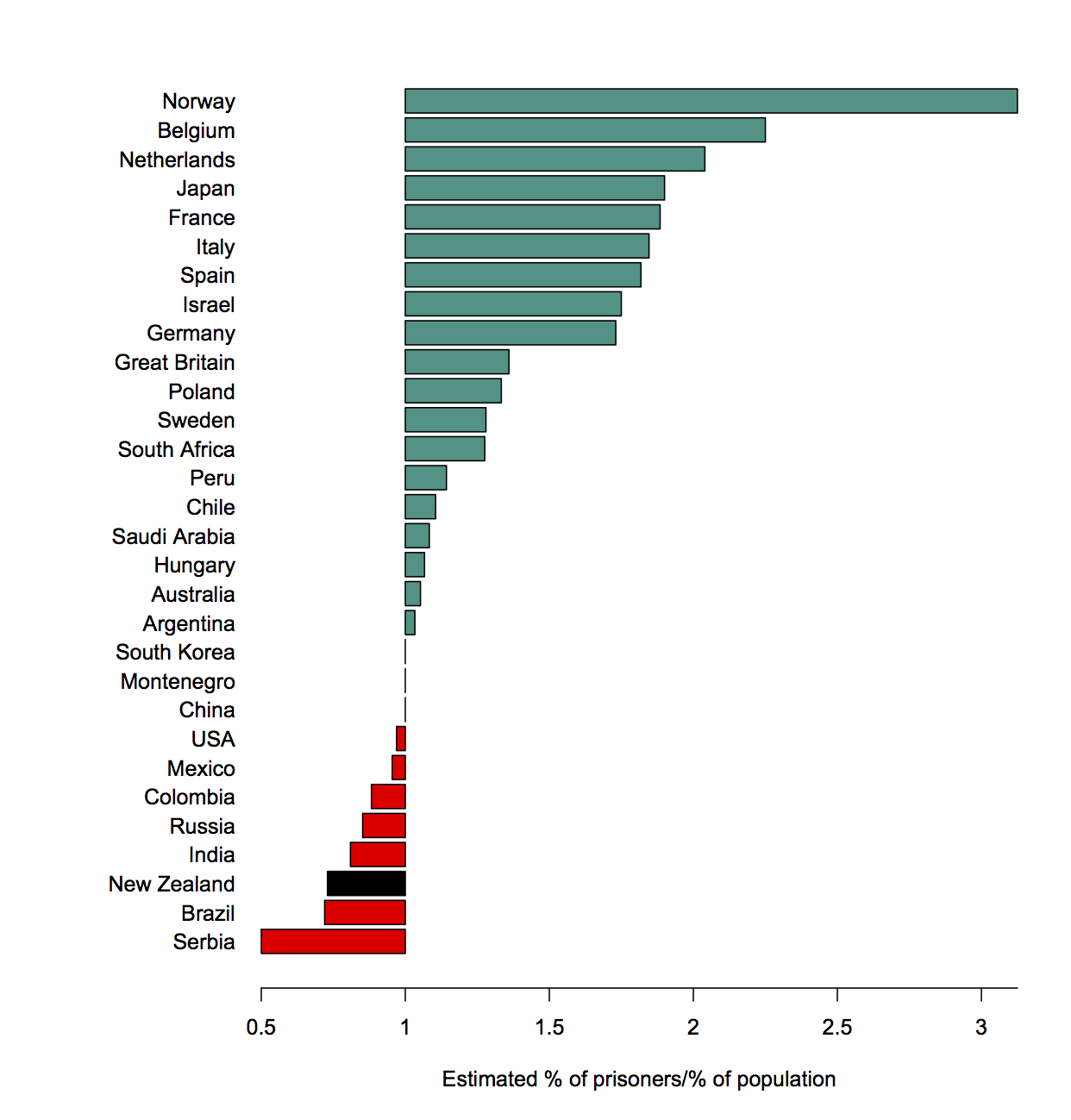
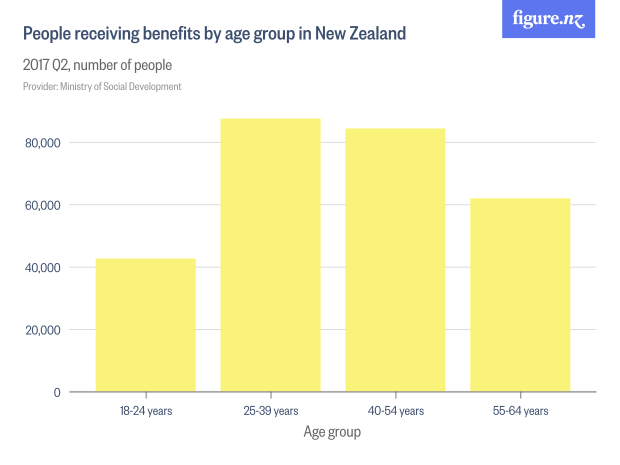
It’s not completely clear what the right scaling is, but raw reports aren’t it. The traditional Kiwi favourite of per capita shows Wellington (city) way ahead of Auckland (region), with more than half as many reports from about an eighth as many people. NZTA is there to represent state highways, and it doesn’t really have a population in the same sense as the other areas.
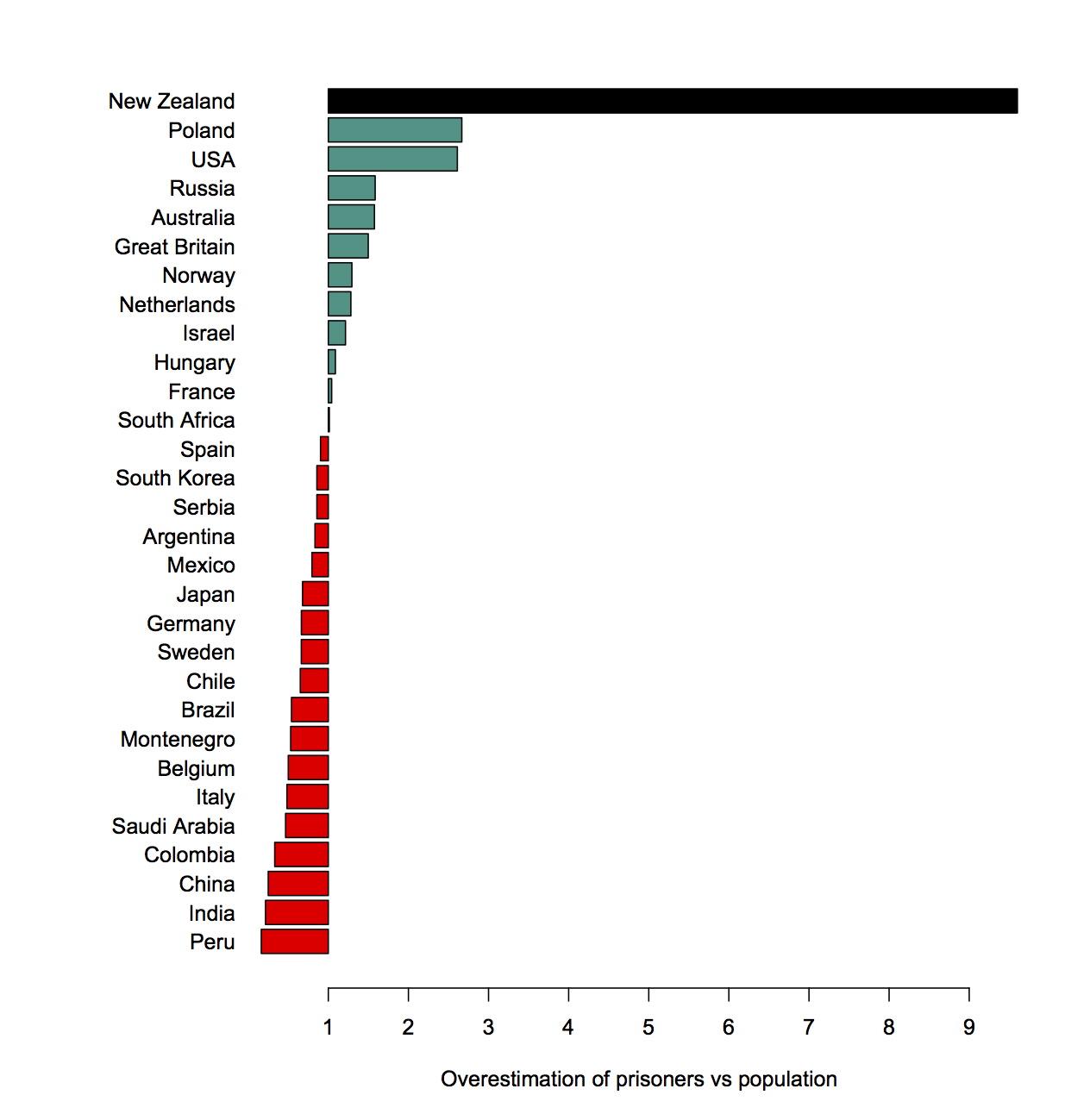
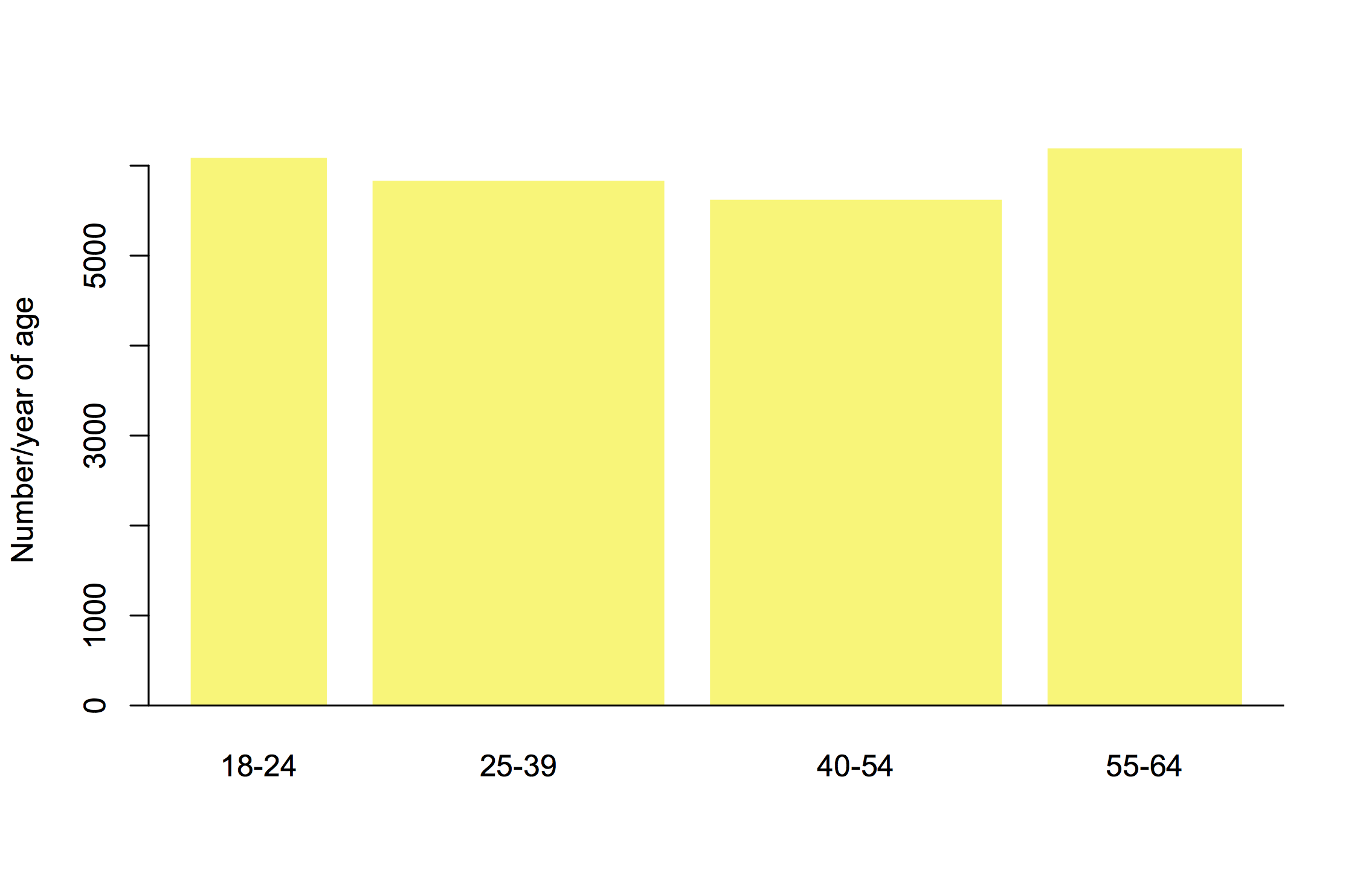
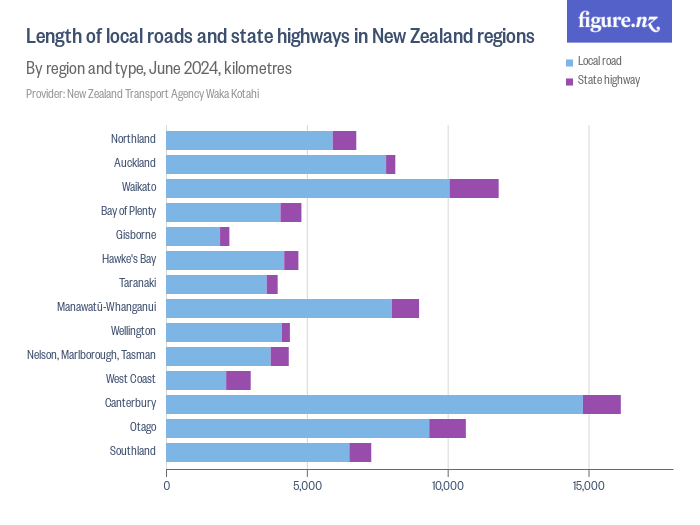
We might also scale by the amount of road to have cones on. This map, from Figure NZ, isn’t quite what we want because it uses consistent geographical units — regions– but it does show how state highway and local roads compare. It looks like NZTA is coning above its weight per km of road
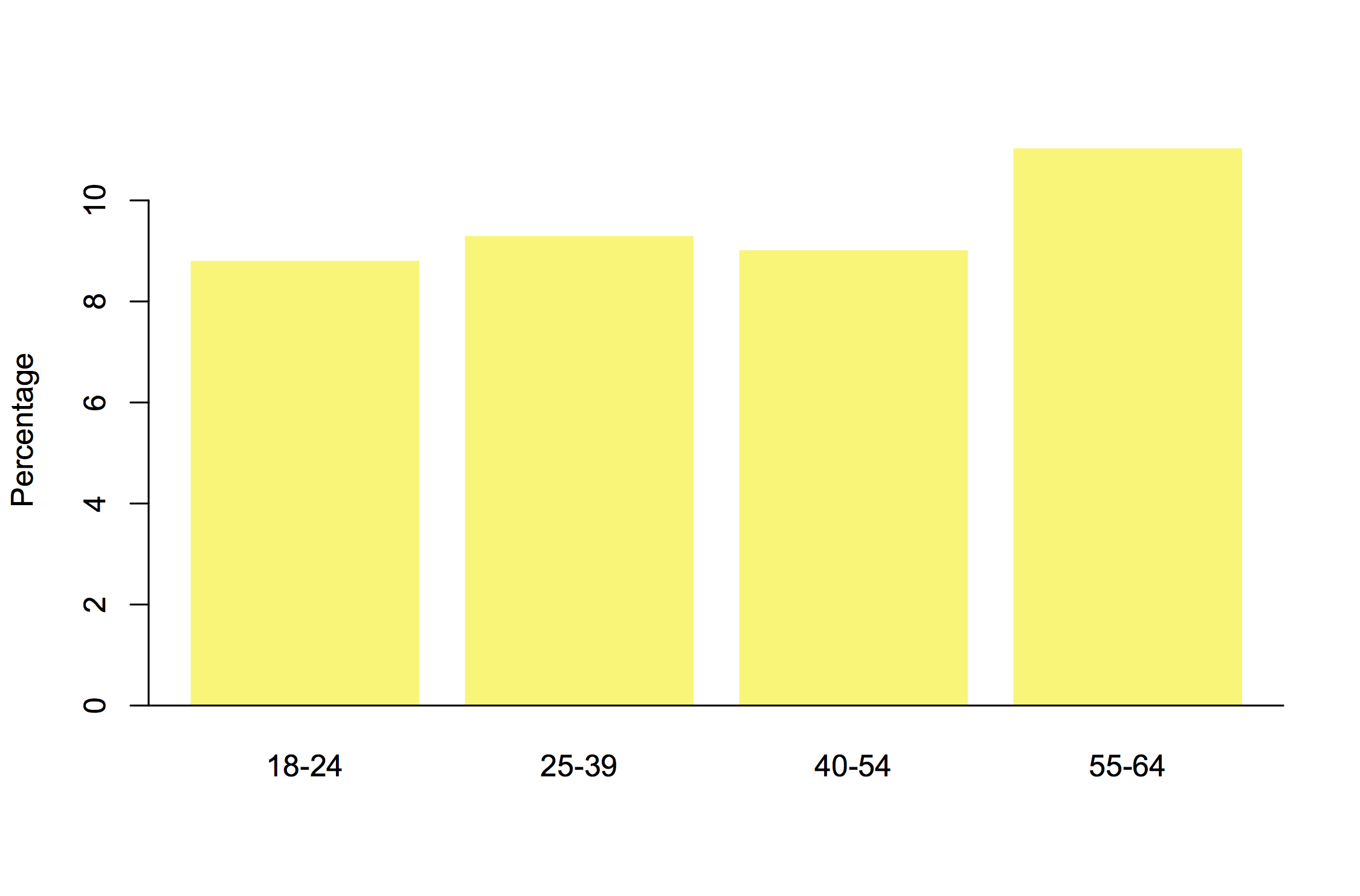
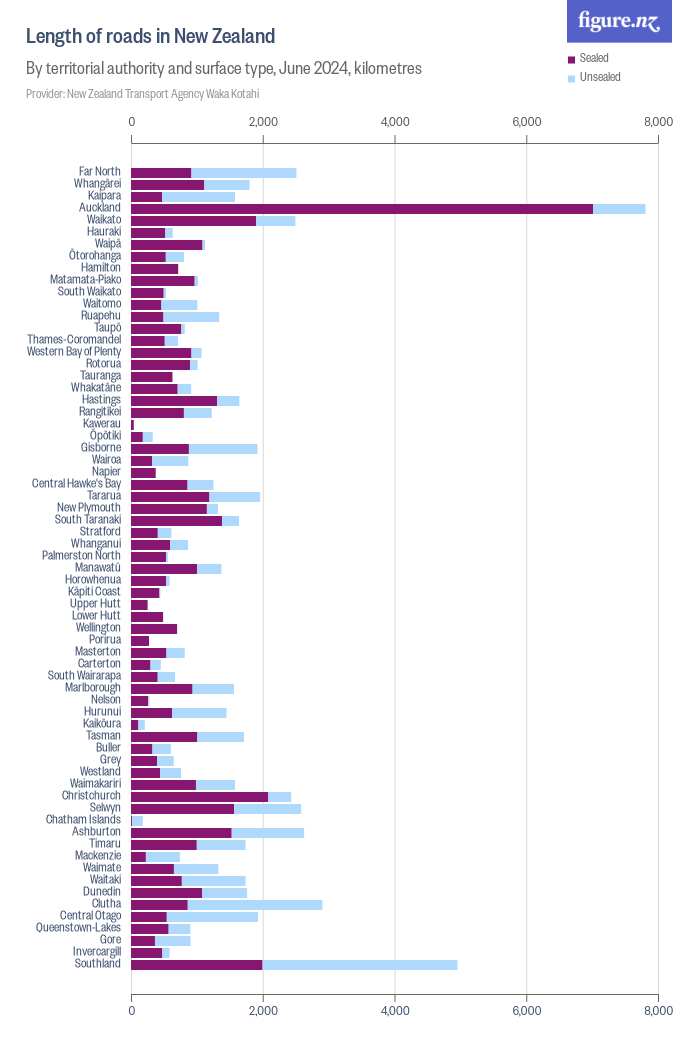
FigureNZ also has a graph by territorial authority, a better match to the Herald’s graph, showing Auckland has well over twice the sealed road of any other authority (if you aren’t a Kiwi: this is ordered north to south). Wellington has much less road, so it is attracting comparatively the most reports.
So, the data do show a “hotspot for cone concerns”, but it’s Wellington, not Auckland. This could mean more cones, or streets with less spare room, or fewer alternate routes, or people who just whinge more. The data do not suffice to tell us.