Predicting the future
As you’ve heard if you’re in NZ, the Treasury got the wrong numbers for predicted impact on child poverty of Labour’s policies (and as you might not have heard, similarly wrong numbers for the previous government’s policies).
Their ‘technical note‘ is useful
In late November and early December 2017, a module was developed to further improve the Accommodation Supplement analysis. This was applied to both the previous Government’s package and the current Government’s Families Package. The coding error occurred in this “add-on module” – in a single line of about 1000 lines of code.
The quality-assurance (QA) process for the add-on module included an independent review of the methodology by a senior statistician outside the Treasury’s microsimulation modelling team, multiple layers of code review, and an independent replication of each stage by two modellers. No issues were identified during this process.
I haven’t seen their code, but I have seen other microsimulation models and as a statistics researcher I’m familiar with the problem of writing and testing code that does a calculation you don’t have any other way to do. In fact, when I got called by Newstalk ZB about the Treasury’s error I was in the middle of talking to a PhD student about how to check code for a new theoretical computation.
It’s relatively straightforward to test code when you know what the output should be for each input: you put in a set of income measurements and see if the right tax comes out, or you click on a link and see if you get taken to the right website, or you shoot the Nazi and see if his head explodes. The most difficult part is thinking of all the things that need to be checked. It’s much harder when you don’t know what the output should even be because the whole point of writing the code is to find out.
You can test chunks of code that are small enough to be simple. You can review the code and try to see if it matches the process that you’re working from. You might be able to work out special cases in some independent way. You can see if the outputs change in sensible ways when you change the inputs. You can get other people to help. And you do all that. And sometimes it isn’t enough.
The Treasury say that they typically try to do more
This QA process, however, is not as rigorous as independent co-production, which is used for modifications of the core microsimulation model. Independent co-production involves two people developing the analysis independently, and cross-referencing their results until they agree. This significantly reduces the risk of errors, but takes longer and was not possible in the time available.
That’s a much stronger verification approach. Personally, I’ve never gone as far as complete independent co-production, but I have done partial versions and it does make you much more confident about the results.
The problem with more rigorous testing approaches is they take time and money and often end up just telling you that you were right. Being less extreme about it is often fine, but maybe isn’t good enough for government work.


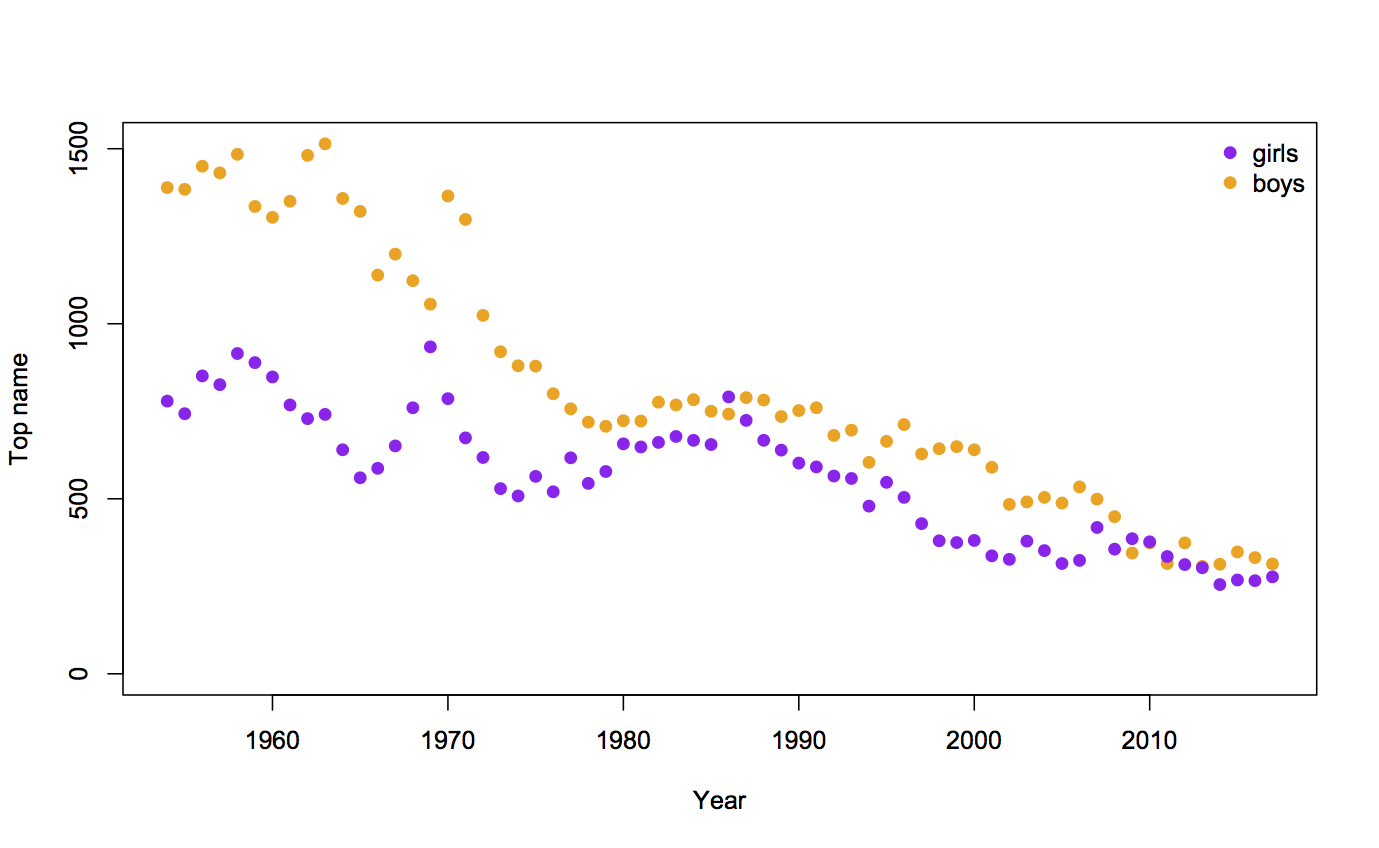
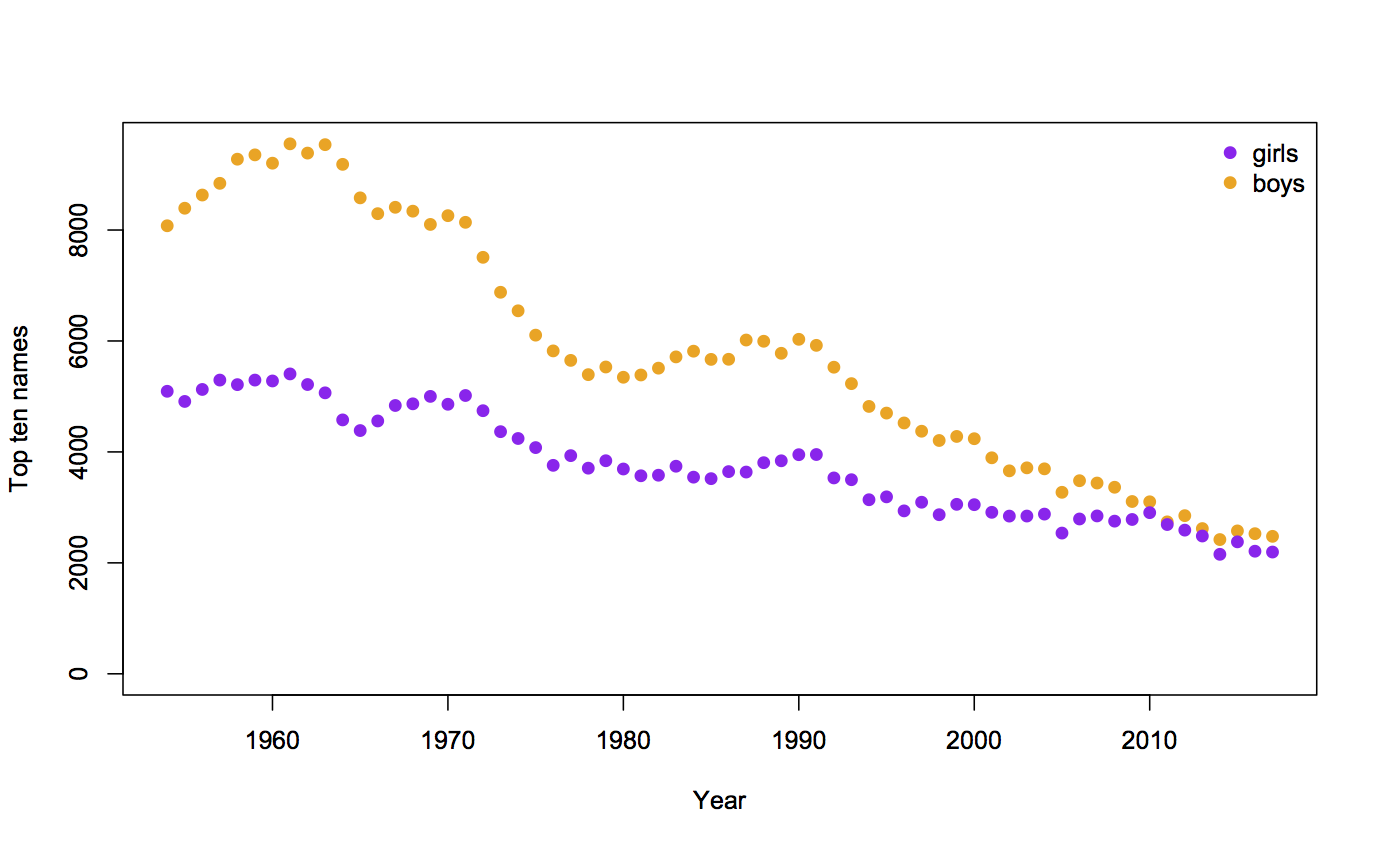
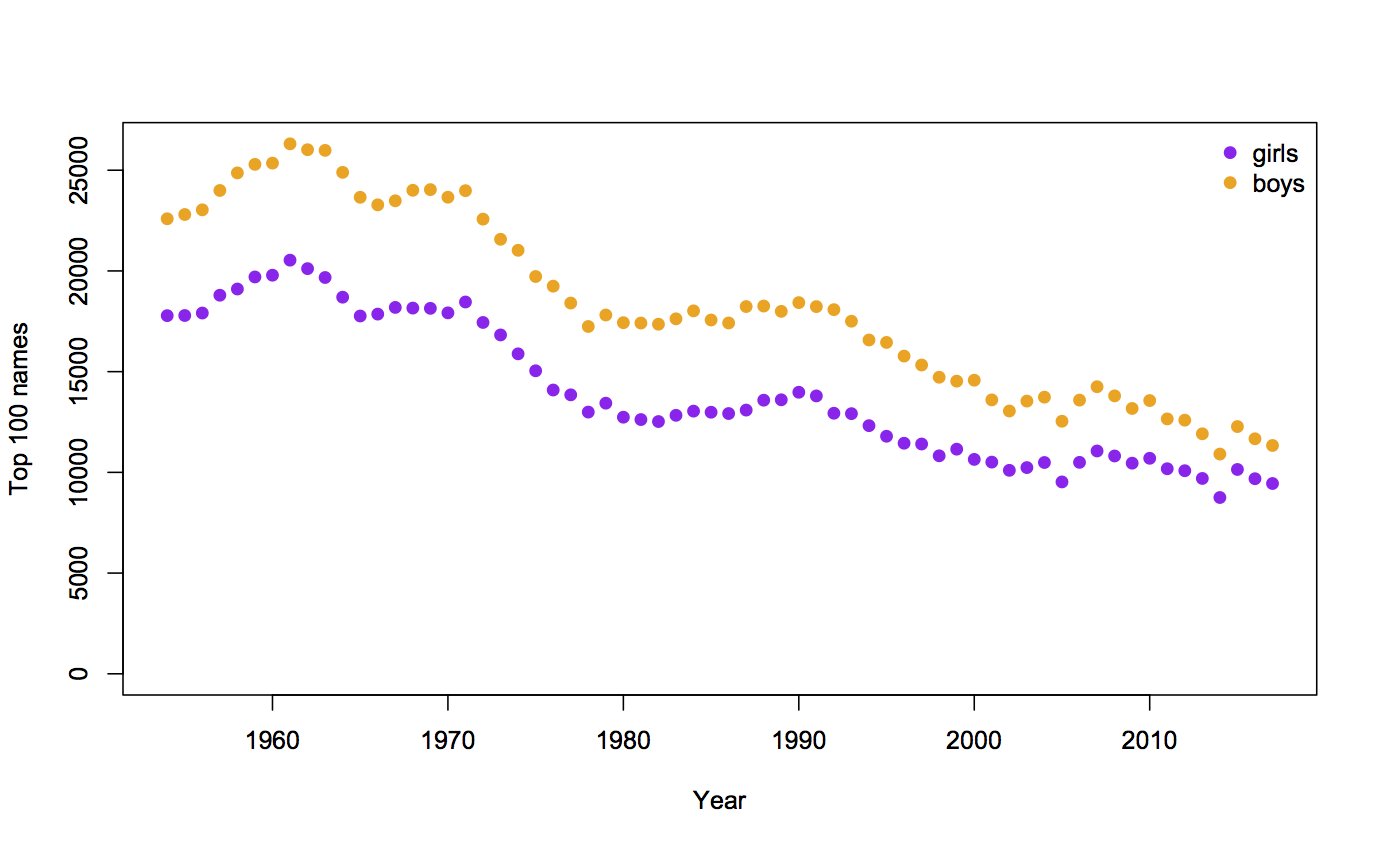
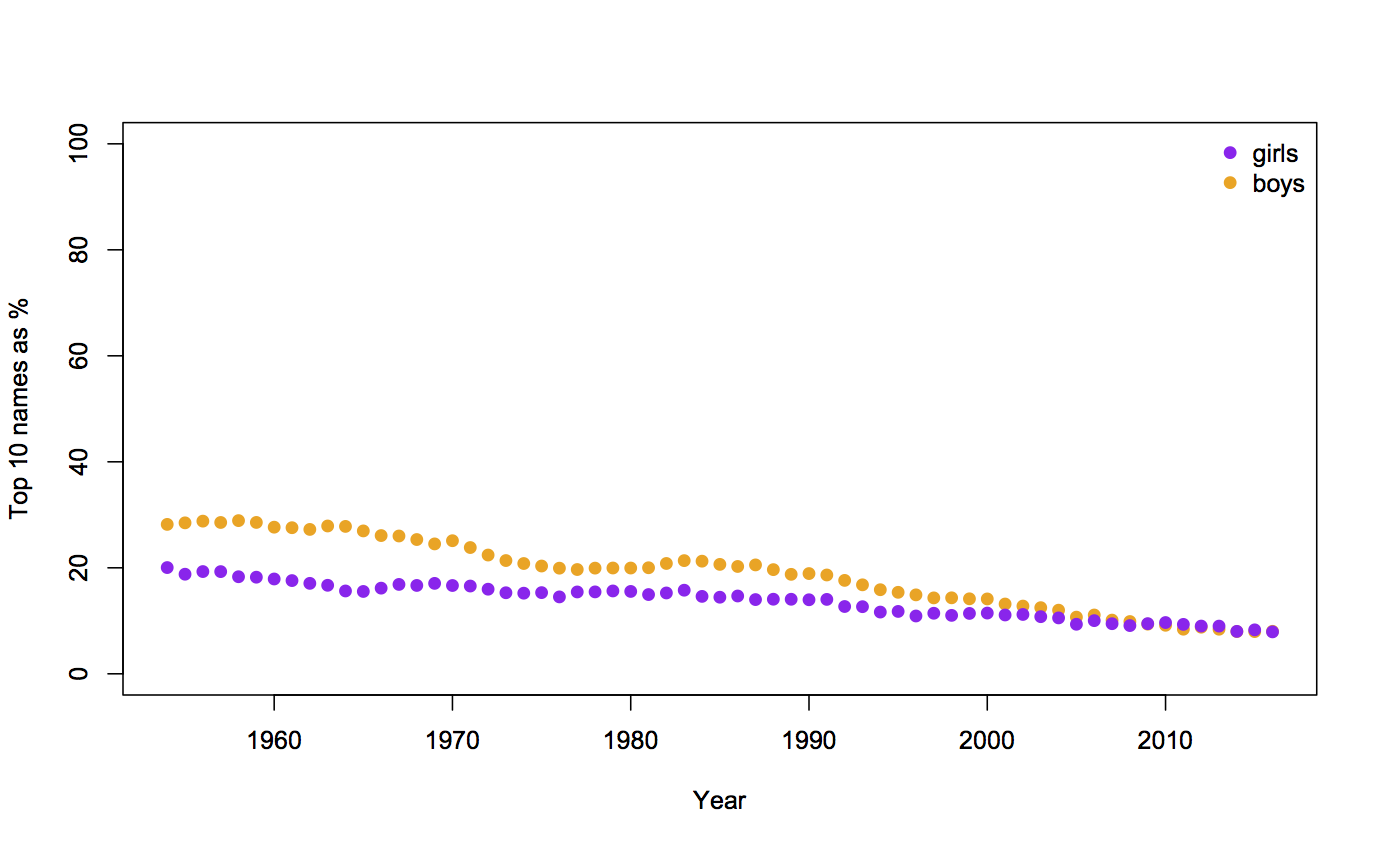
Recent comments